Chapter 2 Summary
2.1 データセット
ここではAmazonの商品レビューのデータセットを使用し、レビューの内容などをもとに、商品カテゴリを目的変数として分類することを試みます。
dt <- data.table::fread("https://s3.amazonaws.com/amazon-reviews-pds/tsv/amazon_reviews_multilingual_JP_v1_00.tsv.gz", quote = "")このデータは、Amazon Customer Reviews Datasetのうち、日本語のレビューだけを抽出したものです。次の15列からなるデータで、欠損値のある行はありません。
marketplace - 2 letter country code of the marketplace where the review was written.
customer_id - Random identifier that can be used to aggregate reviews written by a single author.
review_id - The unique ID of the review.
product_id - The unique Product ID the review pertains to. In the multilingual dataset the reviews
for the same product in different countries can be grouped by the same product_id.
product_parent - Random identifier that can be used to aggregate reviews for the same product.
product_title - Title of the product.
product_category - Broad product category that can be used to group reviews
(also used to group the dataset into coherent parts).
star_rating - The 1-5 star rating of the review.
helpful_votes - Number of helpful votes.
total_votes - Number of total votes the review received.
vine - Review was written as part of the Vine program.
verified_purchase - The review is on a verified purchase.
review_headline - The title of the review.
review_body - The review text.
review_date - The date the review was written.dt |>
dplyr::glimpse()## Rows: 262,431
## Columns: 15
## $ marketplace <chr> "JP", "JP", "JP", "JP", "JP", "JP", "JP", "JP", "JP", "JP", "JP", "…
## $ customer_id <int> 65317, 65317, 65696, 67162, 67701, 68380, 68655, 68973, 69080, 6955…
## $ review_id <chr> "R33RSUD4ZTRKT7", "R2U1VB8GPZBBEH", "R1IBRCJPPGWVJW", "RL02CW5XLYON…
## $ product_id <chr> "B000001GBJ", "B000YPWBQ2", "B0002E5O9G", "B00004SRJ5", "B0093H8H8I…
## $ product_parent <int> 957145596, 904244932, 108978277, 606528497, 509738390, 37188049, 91…
## $ product_title <chr> "SONGS FROM A SECRET GARDE", "鏡の中の鏡‾ペルト作品集(SACD)(Arvo Pa…
## $ product_category <chr> "Music", "Music", "Music", "Music", "PC", "Toys", "Music", "Electro…
## $ star_rating <int> 1, 1, 5, 5, 4, 4, 5, 1, 5, 4, 3, 4, 5, 5, 5, 5, 5, 4, 4, 5, 5, 5, 5…
## $ helpful_votes <int> 1, 4, 2, 6, 2, 2, 8, 3, 1, 1, 3, 0, 6, 1, 4, 1, 1, 3, 7, 8, 2, 1, 0…
## $ total_votes <int> 15, 20, 3, 9, 4, 3, 13, 15, 2, 4, 6, 0, 9, 2, 6, 1, 1, 8, 14, 23, 4…
## $ vine <chr> "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N…
## $ verified_purchase <chr> "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y", "Y…
## $ review_headline <chr> "残念ながら…", "残念ながら…", "ドリームキャスト", "やっぱりマスト…
## $ review_body <chr> "残念ながら…趣味ではありませんでした。ケルト音楽の範疇にも幅がある…
## $ review_date <IDate> 2012-12-05, 2012-12-05, 2013-03-02, 2013-08-11, 2013-02-10, 2014-…2.2 分析
このデータセットには26万2000件ほどのレビューが収録されていますが、レビューのほとんどはVideo DVDカテゴリとMusicカテゴリのものです。その他のカテゴリのレビューをすべて足し合わせても、Musicカテゴリのレビューの数よりも少なく、そもそもレビューが数件しかないようなカテゴリもあります。
また、商品の評価を表す星の数は5を付けているものが過半数であるほか、「このレビューが役に立った」の投票がないものがほとんどになっています。
dt |>
dtplyr::lazy_dt(immutable = TRUE) |>
dplyr::select(review_id, product_category,
star_rating, helpful_votes, total_votes,
vine, verified_purchase,
review_headline, review_body,
review_date) |>
dplyr::mutate(
product_category = forcats::fct_lump(factor(product_category), n = 2),
star_rating = forcats::fct_lump(factor(star_rating), n = 2),
vine = factor(vine),
verified_purchase = factor(verified_purchase),
review_len = nchar(review_body),
review_month = factor(lubridate::month(review_date)),
review_wday = factor(lubridate::wday(review_date, label = TRUE))
) |>
dplyr::select(!c(review_id, review_headline, review_body, review_date)) |>
dplyr::as_tibble() |>
DataExplorer::create_report(output_dir = "docs")レビュー本文は短いものが多く、比較的よくレビューが書かれている商品カテゴリ以外では、とくに短くなりがちです。
dt |>
dtplyr::lazy_dt(immutable = TRUE) |>
dplyr::select(review_id, product_category,
review_headline, review_body) |>
dplyr::mutate(
product_category = factor(product_category),
review_len = nchar(review_body)
) |>
dplyr::filter(review_len > 50, review_len < 2000) |>
dplyr::summarise(
counts = dplyr::n(),
review_len = median(review_len),
.by = product_category
) |>
dplyr::as_tibble() |>
ggplot2::ggplot(ggplot2::aes(x = counts, y = review_len, color = product_category)) +
ggplot2::geom_point() +
ggrepel::geom_text_repel(ggplot2::aes(label = product_category), max.overlaps = 15) +
ggplot2::scale_x_log10() +
ggplot2::theme(legend.position = "none") +
ggplot2::scale_colour_viridis_d(option = "turbo")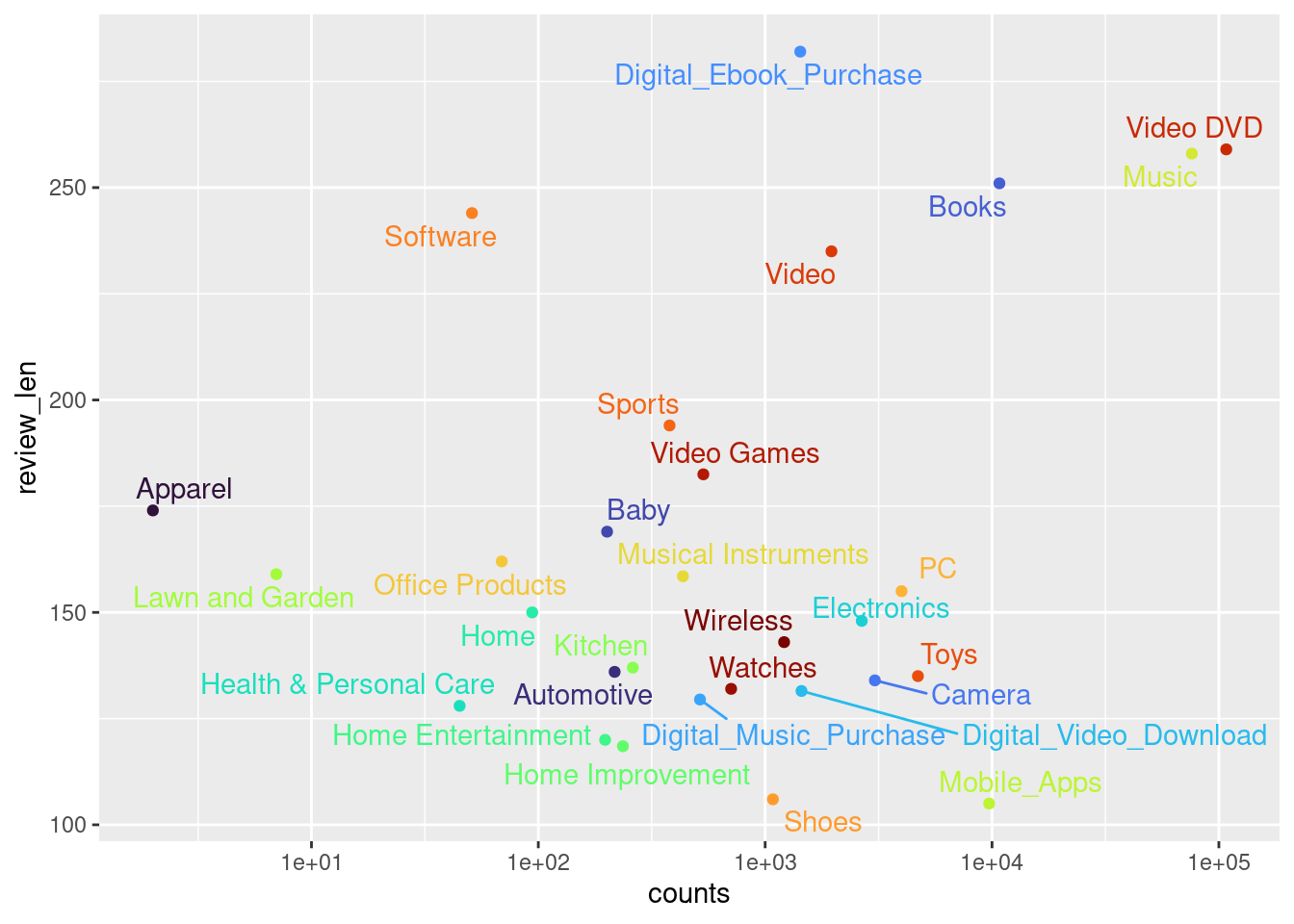
Figure 2.1: Product reviews and their length
分類を簡単にするために、ここでは使用するデータをある程度の文字数のあるレビューに絞りつつ、Video DVDとMusic以外のカテゴリを一つにまとめることにします。
dt |>
dtplyr::lazy_dt(immutable = TRUE) |>
dplyr::select(review_id, product_category,
review_headline, review_body) |>
dplyr::mutate(
product_category = forcats::fct_lump(factor(product_category), n = 2),
review_len = nchar(review_body)
) |>
dplyr::select(product_category, review_len) |>
dplyr::as_tibble() |>
ggpubr::ggdensity(
"review_len",
y = "density",
color = "product_category",
palette = viridisLite::turbo(3)
) |>
ggpubr::ggpar(xscale = "log10")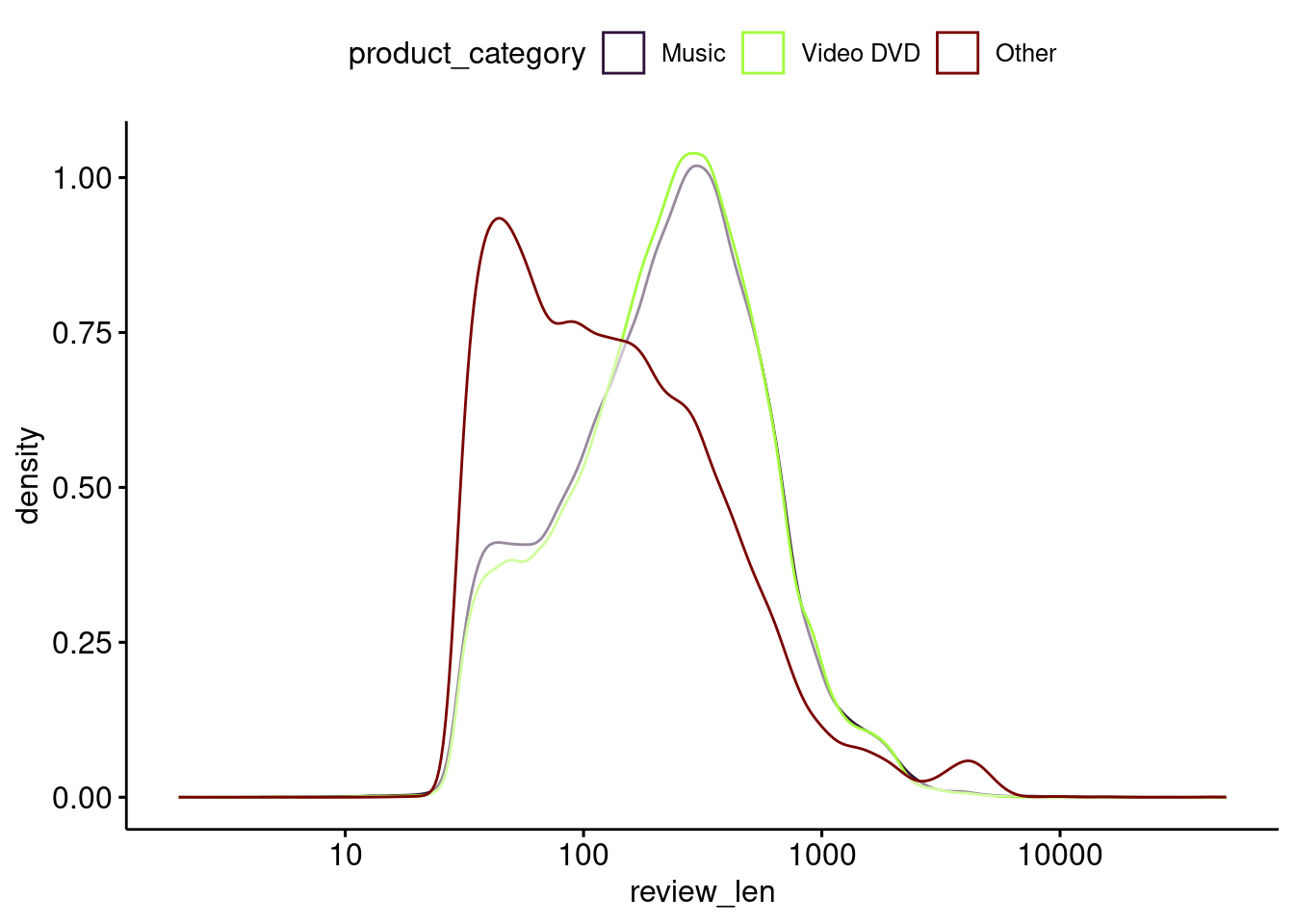
Figure 2.2: Density of review length