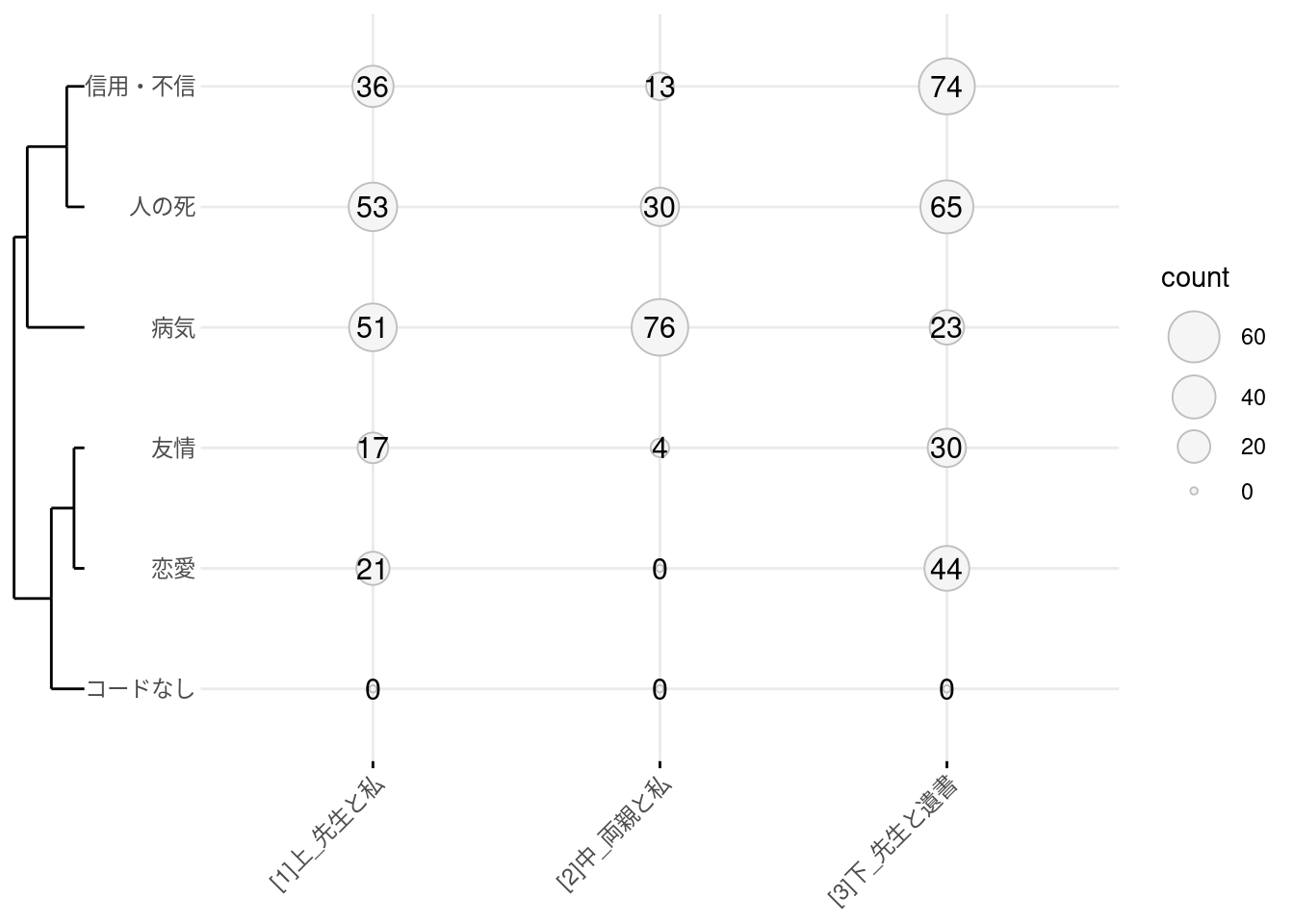
dfm |> keyATM::keyATM_read(check =FALSE) |> keyATM::visualize_keywords(rules)#> ℹ Using quanteda dfm.#> Warning: Keywords are pruned because they do not appear in the documents: 死後, 自殺,#> 殉死, 頓死, 変死, 亡, 恋愛, 失恋, 恋しい, 病気, 看病, and 大病
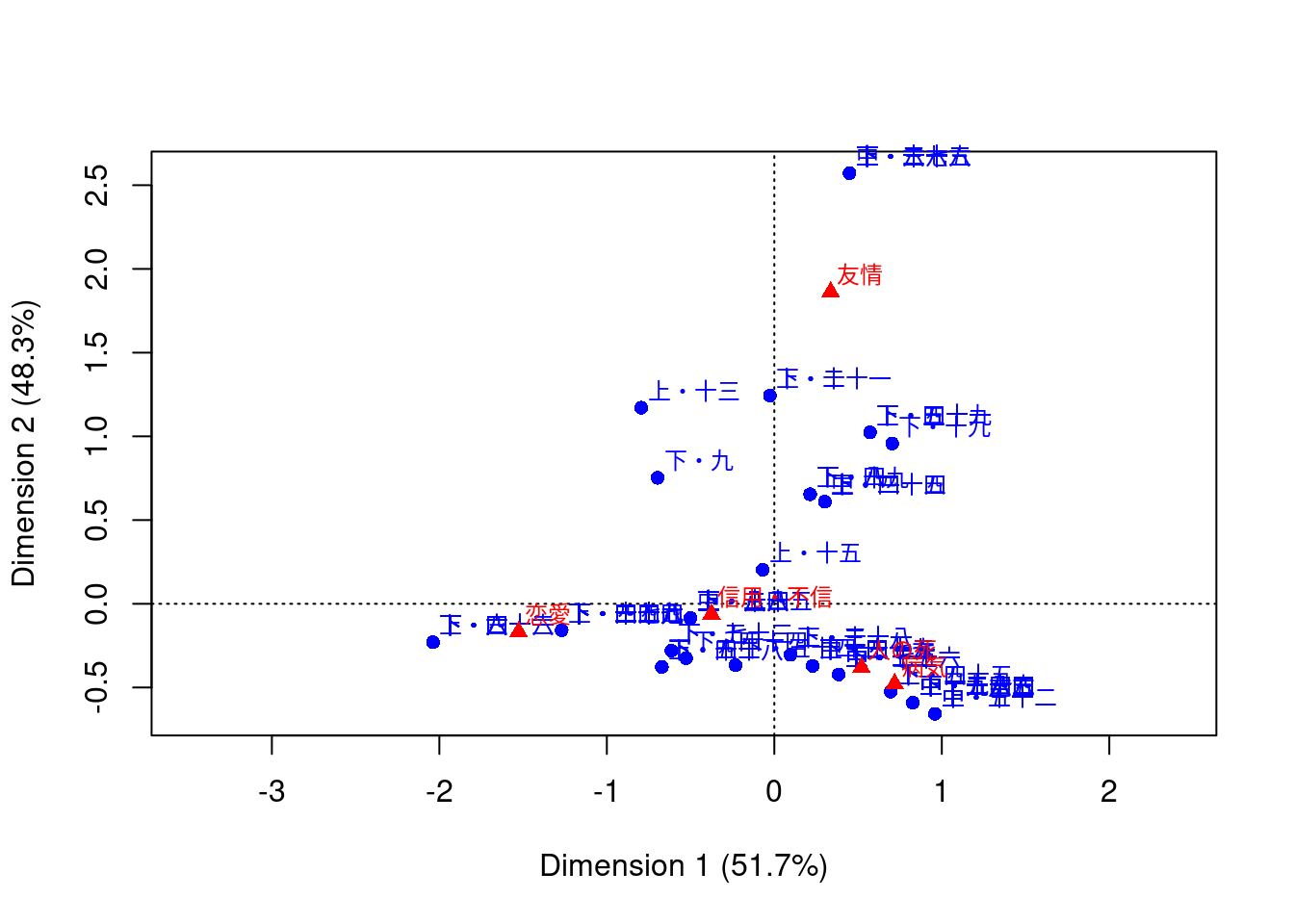
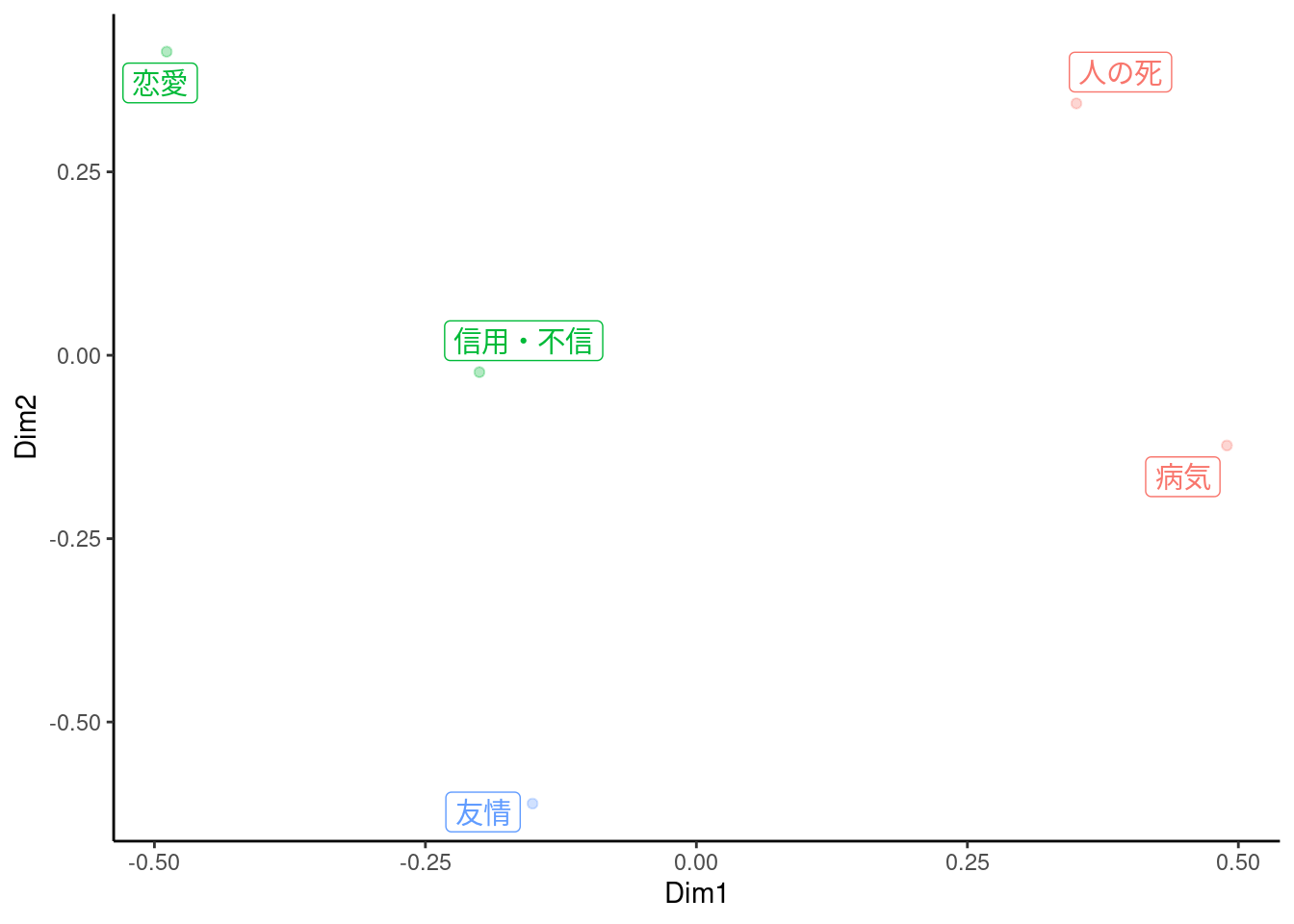
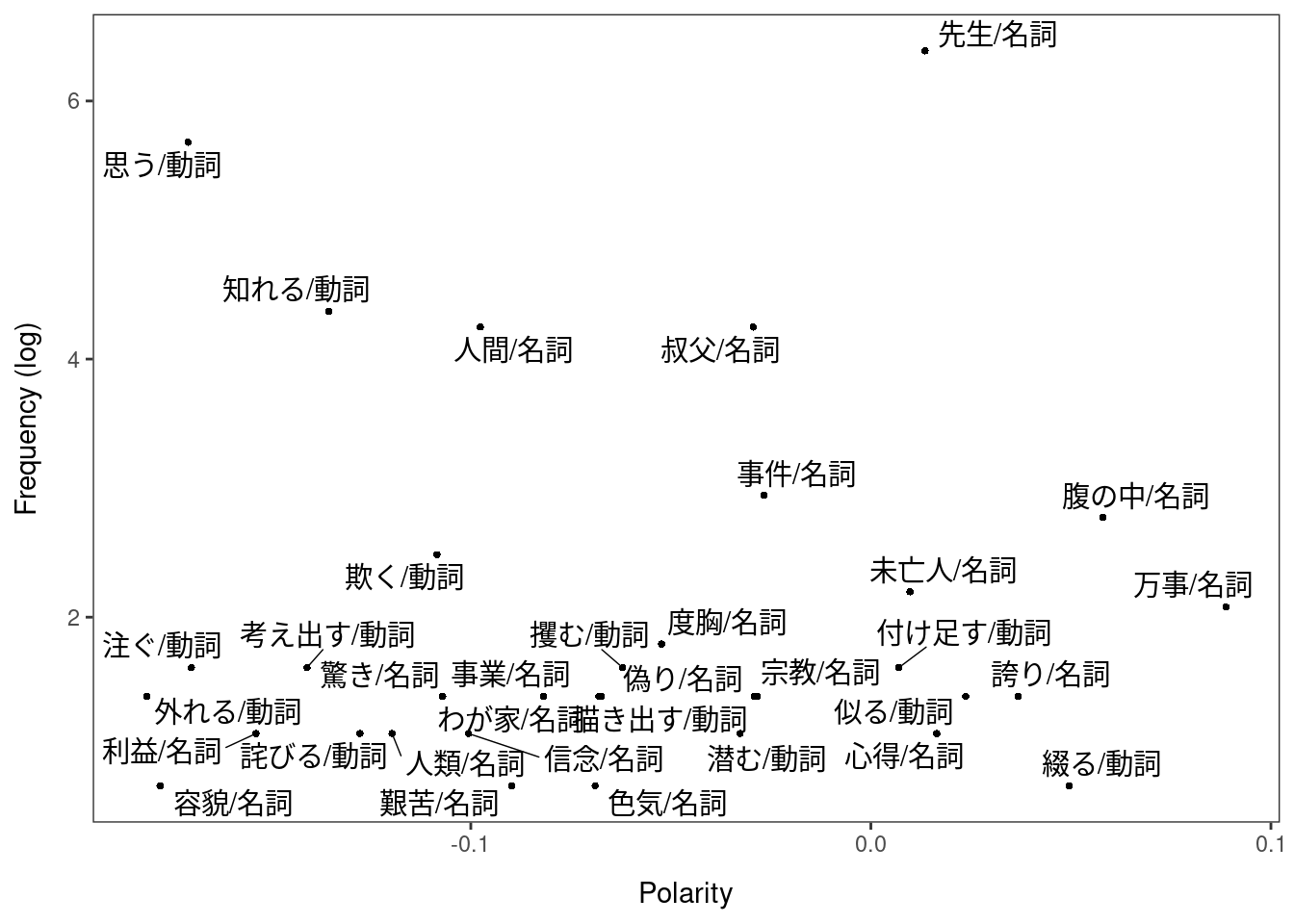
keyatm_fit <- dfm |> keyATM::keyATM_read(check =FALSE) |> keyATM::keyATM( rules,no_keyword_topics =6,model ="base",options =list(seed =123,iterations =2000,verbose =FALSE ) )#> ℹ Using quanteda dfm.#> ⠙ Initializing the model#> Warning: Upper case letters are used. Please review preprocessing steps.#> Warning: Keywords are pruned because they do not appear in the documents: 死後, 自殺,#> 殉死, 頓死, 変死, 亡, 恋愛, 失恋, 恋しい, 病気, 看病, and 大病#> ✔ Initializing the model [281ms]#> #> ⠙ Fitting the model: 2000 iterations#> Fitting the model ■■■■■ 14% | ETA: 9s#> Fitting the model ■■■■■■■■■■■■■■ 44% | ETA: 6s#> Fitting the model ■■■■■■■■■■■■■■■■■■■■■■■ 74% | ETA: 3s#> ⠙ Fitting the model: 2000 iterations✔ Fitting the model:2000 iterations [10s]#> #> ⠙ Creating an output object#> ✔ Creating an output object [292ms]