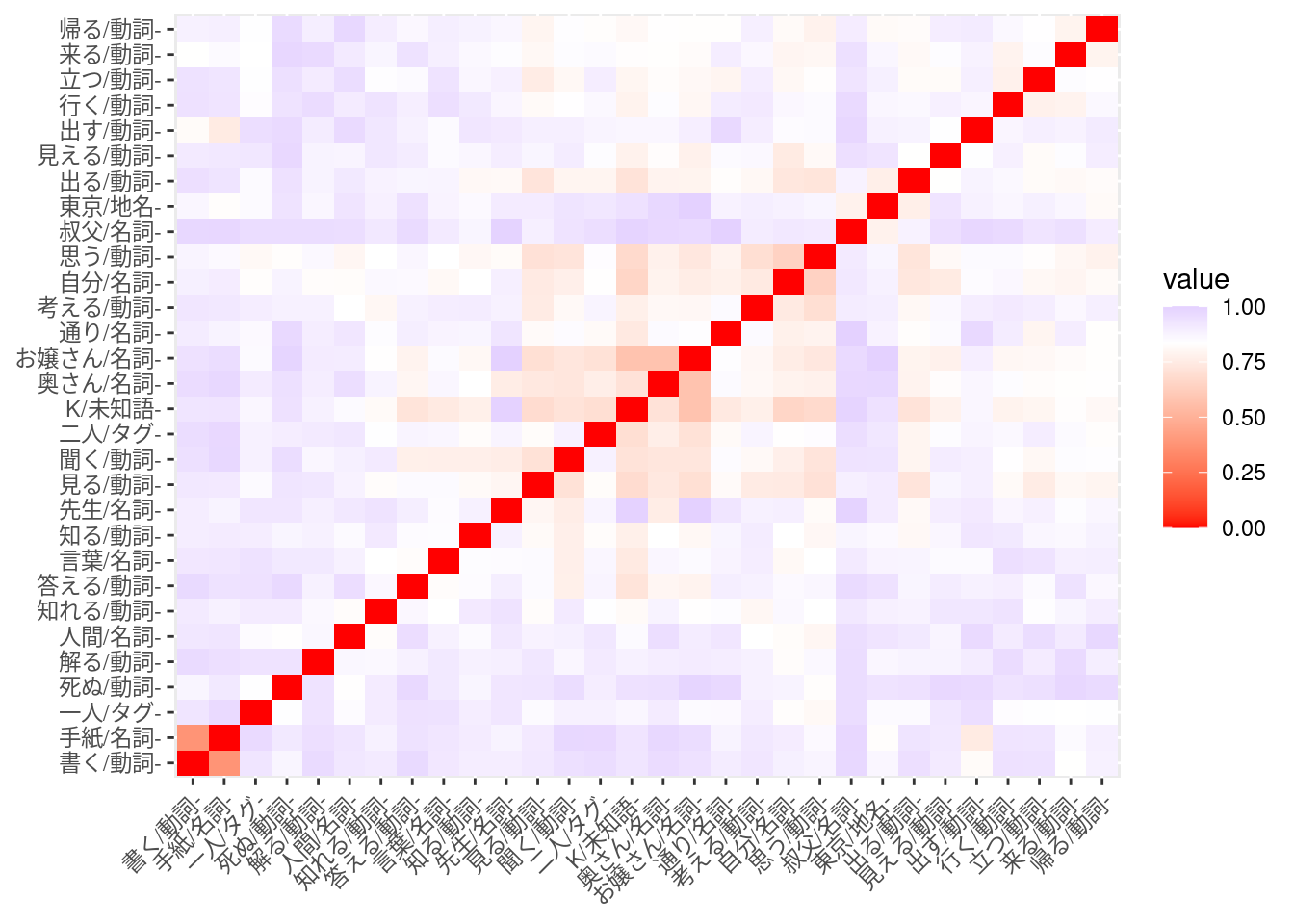
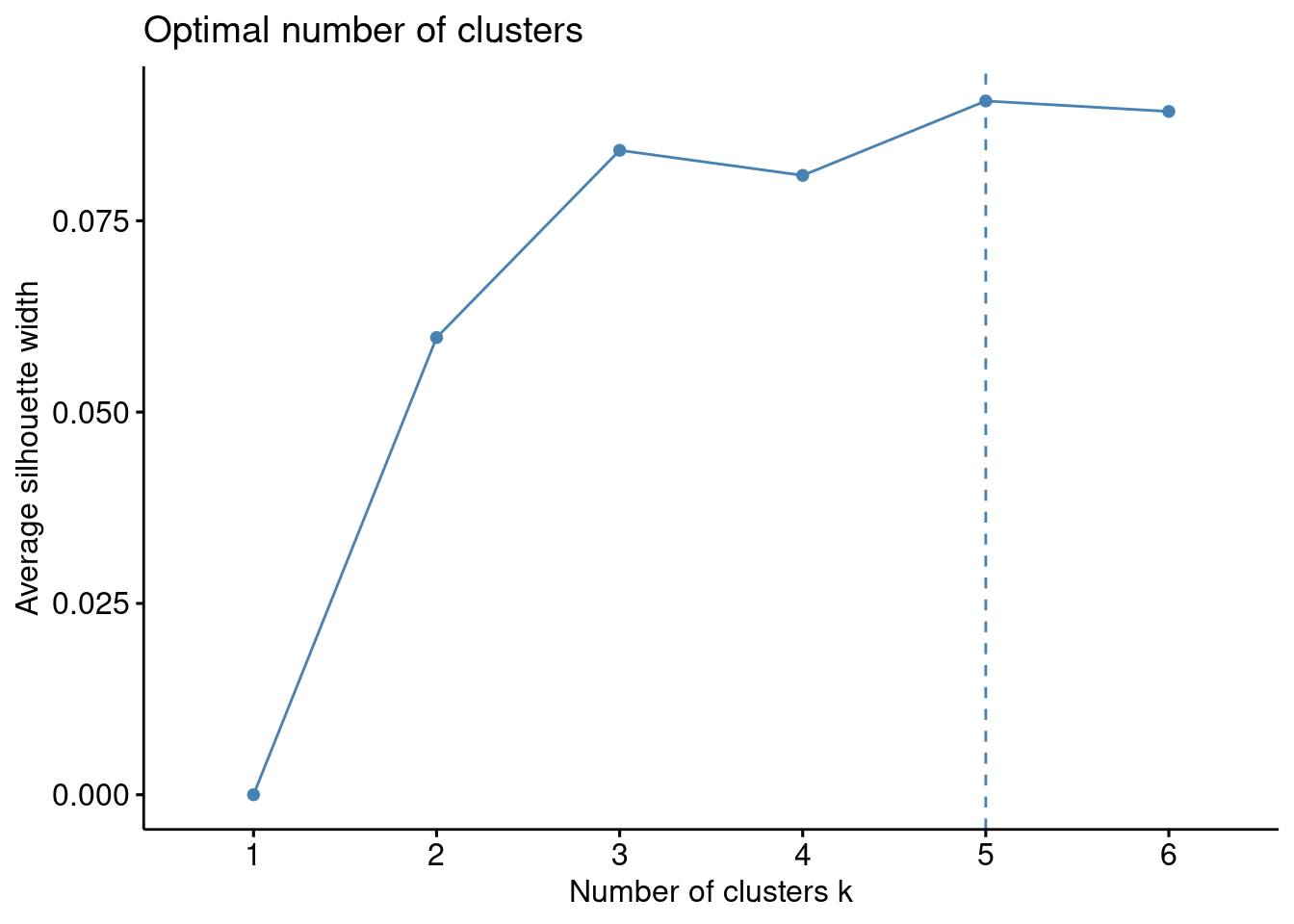
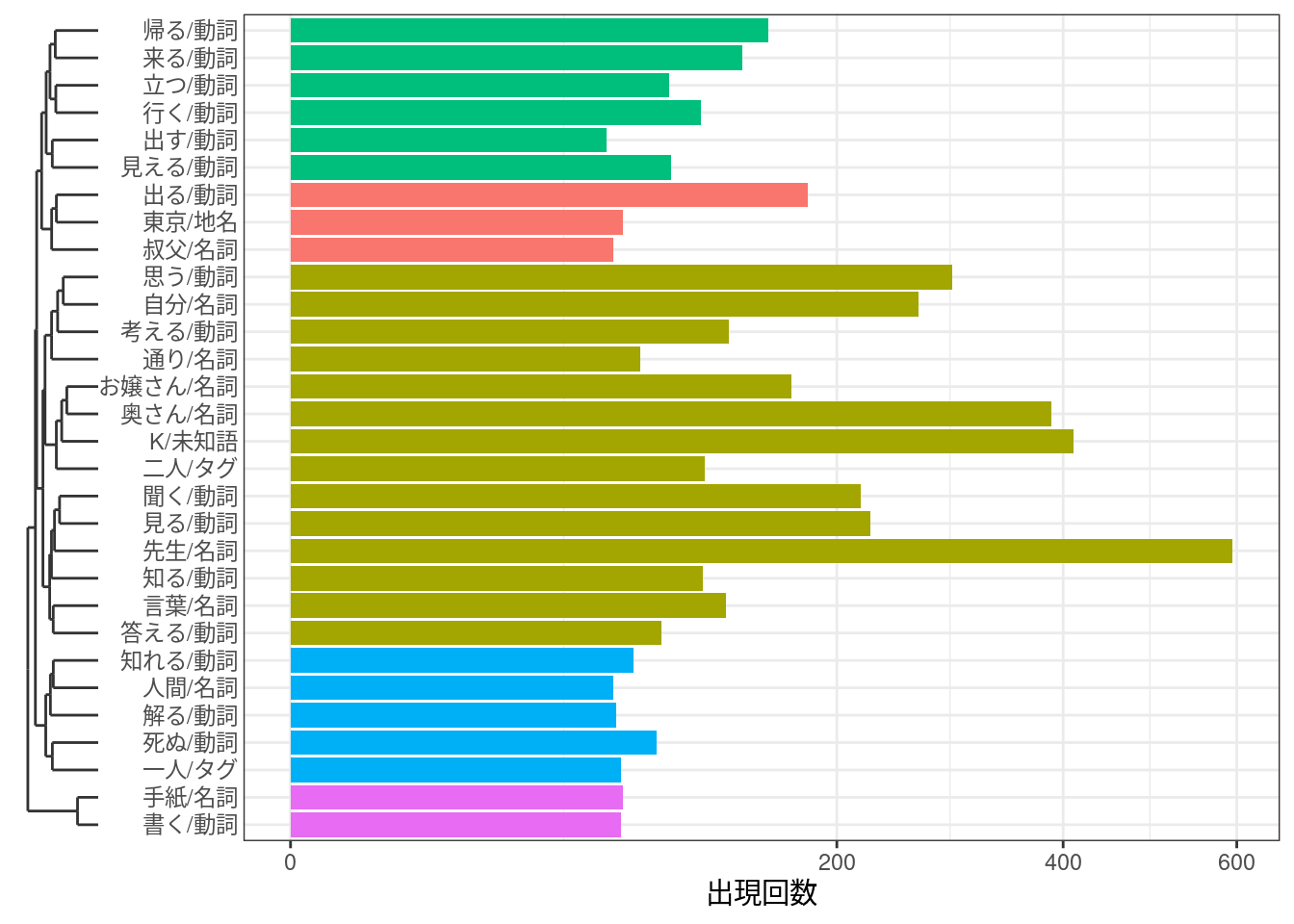
factoextra::fviz_dend(clusters, k =5, horiz =TRUE, labels_track_height =0.3)#> Warning in seq.default(15, 375, length = k + 1): 'length' の 'length.out'#> への部分的な引数のマッチング#> Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as#> of ggplot2 3.3.4.#> ℹ The deprecated feature was likely used in the factoextra package.#> Please report the issue at <https://github.com/kassambara/factoextra/issues>.
dfm |> quanteda::dfm_trim(min_termfreq =30, termfreq_type ="rank") |> quanteda::colSums() |> tibble::enframe() |> dplyr::mutate(clust = (clusters |>cutree(k =5))[name] ) |>ggplot(aes(x = value, y = name, fill =factor(clust))) +geom_bar(stat ="identity", show.legend =FALSE) +scale_x_sqrt() + ggh4x::scale_y_dendrogram(hclust = clusters) +labs(x ="出現回数", y =element_blank()) +theme_bw()#> Warning: The S3 guide system was deprecated in ggplot2 3.5.0.#> ℹ It has been replaced by a ggproto system that can be extended.