suppressPackageStartupMessages({
library(ggplot2)
library(ca)
library(duckdb)
})
drv <- duckdb::duckdb()
con <- duckdb::dbConnect(drv, dbdir = "tutorial_jp/kokoro.duckdb", read_only = TRUE)
tbl <-
readxl::read_xls("tutorial_jp/kokoro.xls",
col_names = c("text", "section", "chapter", "label"),
skip = 1
) |>
dplyr::mutate(
doc_id = factor(dplyr::row_number()),
dplyr::across(where(is.character), ~ audubon::strj_normalize(.))
) |>
dplyr::filter(!gibasa::is_blank(text)) |>
dplyr::relocate(doc_id, text, section, label, chapter)Appendix F — コーディングメニュー
F.1 単純集計(A.7.1)
rules <- list(
"人の死" = c("死後", "死病", "死期", "死因", "死骸", "生死", "自殺", "殉死", "頓死", "変死", "亡", "死ぬ", "亡くなる", "殺す", "亡くす", "死"),
"恋愛" = c("愛", "恋", "愛す", "愛情", "恋人", "愛人", "恋愛", "失恋", "恋しい"),
"友情" = c("友達", "友人", "旧友", "親友", "朋友", "友", "級友"),
"信用・不信" = c("信用", "信じる", "信ずる", "不信", "疑い", "疑惑", "疑念", "猜疑", "狐疑", "疑問", "疑い深い", "疑う", "疑る", "警戒"),
"病気" = c("医者", "病人", "病室", "病院", "病症", "病状", "持病", "死病", "主治医", "精神病", "仮病", "病気", "看病", "大病", "病む", "病")
) |>
quanteda::dictionary()
dfm <-
dplyr::tbl(con, "tokens") |>
dplyr::mutate(token = dplyr::if_else(is.na(original), token, original)) |>
dplyr::count(doc_id, token) |>
dplyr::collect() |>
tidytext::cast_dfm(doc_id, token, n) |>
quanteda::dfm_lookup(rules)
dfm |>
quanteda::convert(to = "data.frame") |>
dplyr::mutate(`コードなし` = as.numeric(rowSums(dplyr::pick(where(is.numeric))) == 0)) |>
tidyr::pivot_longer(cols = !doc_id, names_to = "code", values_to = "count") |>
dplyr::summarise(
total = sum(count),
prop = total / dplyr::n(),
.by = code
)
#> # A tibble: 6 × 3
#> code total prop
#> <chr> <dbl> <dbl>
#> 1 人の死 148 0.122
#> 2 恋愛 65 0.0536
#> 3 友情 51 0.0420
#> 4 信用・不信 123 0.101
#> 5 病気 150 0.124
#> 6 コードなし 919 0.758F.2 クロス集計(A.7.2)
F.2.1 クロス表
dfm <-
dplyr::tbl(con, "tokens") |>
dplyr::mutate(token = dplyr::if_else(is.na(original), token, original)) |>
dplyr::count(label, token) |>
dplyr::collect() |>
tidytext::cast_dfm(label, token, n) |>
quanteda::dfm_lookup(rules)
dfm |>
quanteda::convert(to = "data.frame") |>
dplyr::mutate(`コードなし` = as.numeric(rowSums(dplyr::pick(where(is.numeric))) == 0)) |>
tidyr::pivot_longer(cols = !doc_id, names_to = "code", values_to = "count") |>
dplyr::left_join(
dplyr::distinct(tbl, label, section),
by = dplyr::join_by(doc_id == label)
) |>
tidyr::uncount(count) |>
crosstable::crosstable(section, by = code, total = "both") |>
crosstable::as_flextable()label | variable | code | Total | |||||
|---|---|---|---|---|---|---|---|---|
コードなし | 信用・不信 | 人の死 | 病気 | 友情 | 恋愛 | |||
section | [1]上_先生と私 | 6 (3.26%) | 36 (19.57%) | 53 (28.80%) | 51 (27.72%) | 17 (9.24%) | 21 (11.41%) | 184 (33.21%) |
[2]中_両親と私 | 0 (0%) | 13 (10.57%) | 30 (24.39%) | 76 (61.79%) | 4 (3.25%) | 0 (0%) | 123 (22.20%) | |
[3]下_先生と遺書 | 11 (4.45%) | 74 (29.96%) | 65 (26.32%) | 23 (9.31%) | 30 (12.15%) | 44 (17.81%) | 247 (44.58%) | |
Total | 17 (3.07%) | 123 (22.20%) | 148 (26.71%) | 150 (27.08%) | 51 (9.21%) | 65 (11.73%) | 554 (100%) | |
F.2.2 ヒートマップ
横に長すぎてラベルが見づらいです。
dfm |>
quanteda::convert(to = "data.frame") |>
dplyr::mutate(`コードなし` = as.numeric(rowSums(dplyr::pick(where(is.numeric))) == 0)) |>
tidyr::pivot_longer(cols = !doc_id, names_to = "code", values_to = "count") |>
dplyr::filter(count > 0) |>
ggplot(aes(x = factor(doc_id, levels = unique(tbl$label)), y = code)) +
geom_raster(aes(fill = count)) +
labs(x = element_blank(), y = element_blank()) +
theme_classic() +
theme(axis.text.x = element_text(angle = 90, vjust = 1, hjust = 1))
#> Warning: `label` cannot be a <ggplot2::element_blank> object.
#> `label` cannot be a <ggplot2::element_blank> object.
F.2.3 バルーンプロット
dfm <-
dplyr::tbl(con, "tokens") |>
dplyr::mutate(token = dplyr::if_else(is.na(original), token, original)) |>
dplyr::count(section, token) |>
dplyr::collect() |>
tidytext::cast_dfm(section, token, n) |>
quanteda::dfm_lookup(rules)
dat <- dfm |>
quanteda::convert(to = "data.frame") |>
dplyr::mutate(`コードなし` = as.numeric(rowSums(dplyr::pick(where(is.numeric))) == 0)) |>
tidyr::pivot_longer(cols = !doc_id, names_to = "code", values_to = "count")
clusters <- dat |>
tidytext::cast_dfm(doc_id, code, count) |>
proxyC::dist(margin = 2, method = "euclidean") |>
as.dist() |>
hclust(method = "ward.D2")
dat |>
ggpubr::ggballoonplot(x = "doc_id", y = "code", size = "count", color = "gray", fill = "#f5f5f5", show.label = TRUE) +
legendry::scale_y_dendro(clust = clusters)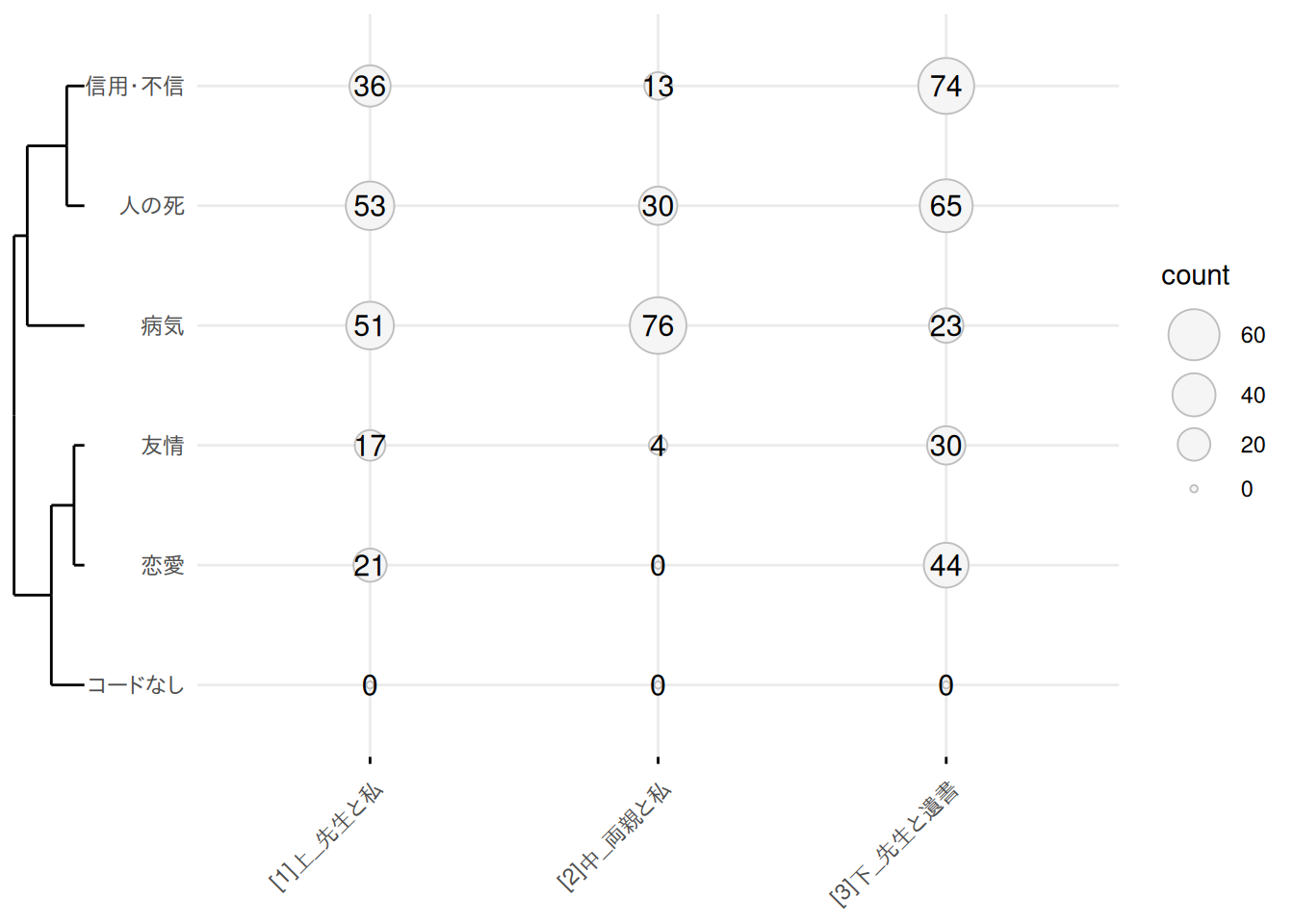
F.3 類似度行列(A.7.3)
dfm <-
dplyr::tbl(con, "tokens") |>
dplyr::mutate(token = dplyr::if_else(is.na(original), token, original)) |>
dplyr::count(label, token) |>
dplyr::collect() |>
tidytext::cast_dfm(label, token, n) |>
quanteda::dfm_lookup(rules) |>
quanteda::dfm_weight(scheme = "boolean")
quanteda.textstats::textstat_simil(dfm, margin = "features", method = "jaccard")
#> textstat_simil object; method = "jaccard"
#> 人の死 恋愛 友情 信用・不信 病気
#> 人の死 1.000 0.1129 0.1186 0.253 0.4310
#> 恋愛 0.113 1.0000 0.0652 0.283 0.0476
#> 友情 0.119 0.0652 1.0000 0.175 0.1053
#> 信用・不信 0.253 0.2833 0.1746 1.000 0.2817
#> 病気 0.431 0.0476 0.1053 0.282 1.0000F.4 その他の分析(A.7.4-8)
基本的に抽出語メニューのときと同じやり方でグラフをつくることができるはずです。階層的クラスター分析、共起ネットワーク、SOMについては省略しています。
F.4.1 対応分析
library(ca)
quanteda.textmodels::textmodel_ca(dfm, nd = 2, sparse = TRUE) |>
plot()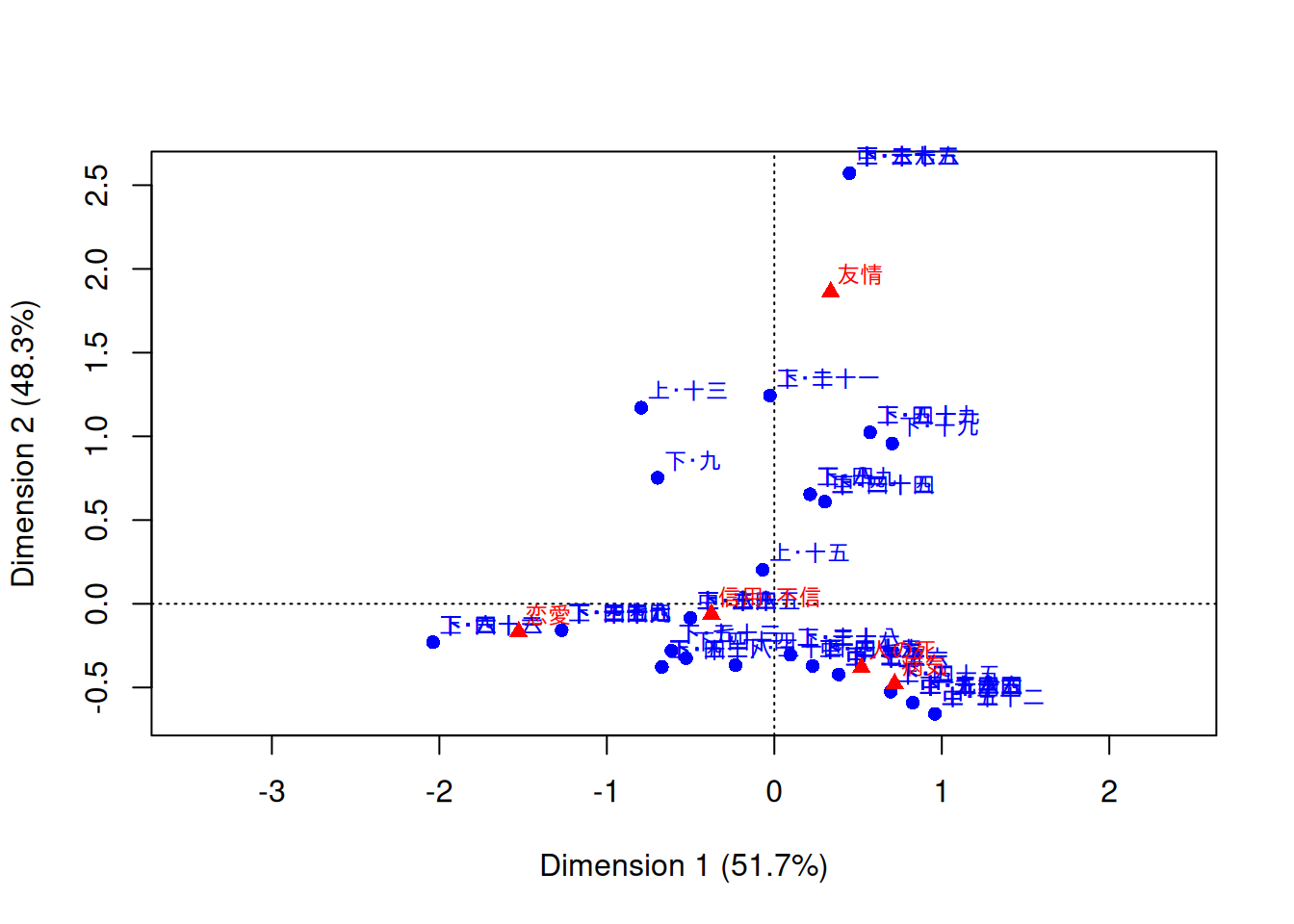
F.4.2 多次元尺度構成法(MDS)
simil <- dfm |>
proxyC::simil(margin = 2, method = "jaccard")
dat <- MASS::sammon(1 - simil, k = 2) |>
purrr::pluck("points")
#> Initial stress : 0.09511
#> stress after 10 iters: 0.03043, magic = 0.500
#> stress after 20 iters: 0.03038, magic = 0.500dat <- dat |>
dplyr::as_tibble(
rownames = "label",
.name_repair = ~ c("Dim1", "Dim2")
) |>
dplyr::mutate(
clust = (hclust(
proxyC::dist(dat, method = "euclidean") |> as.dist(),
method = "ward.D2"
) |> cutree(k = 3))[label]
)
dat |>
ggplot(aes(x = Dim1, y = Dim2, label = label, col = factor(clust))) +
geom_point(alpha = .3, show.legend = FALSE) +
ggrepel::geom_label_repel(show.legend = FALSE) +
theme_classic()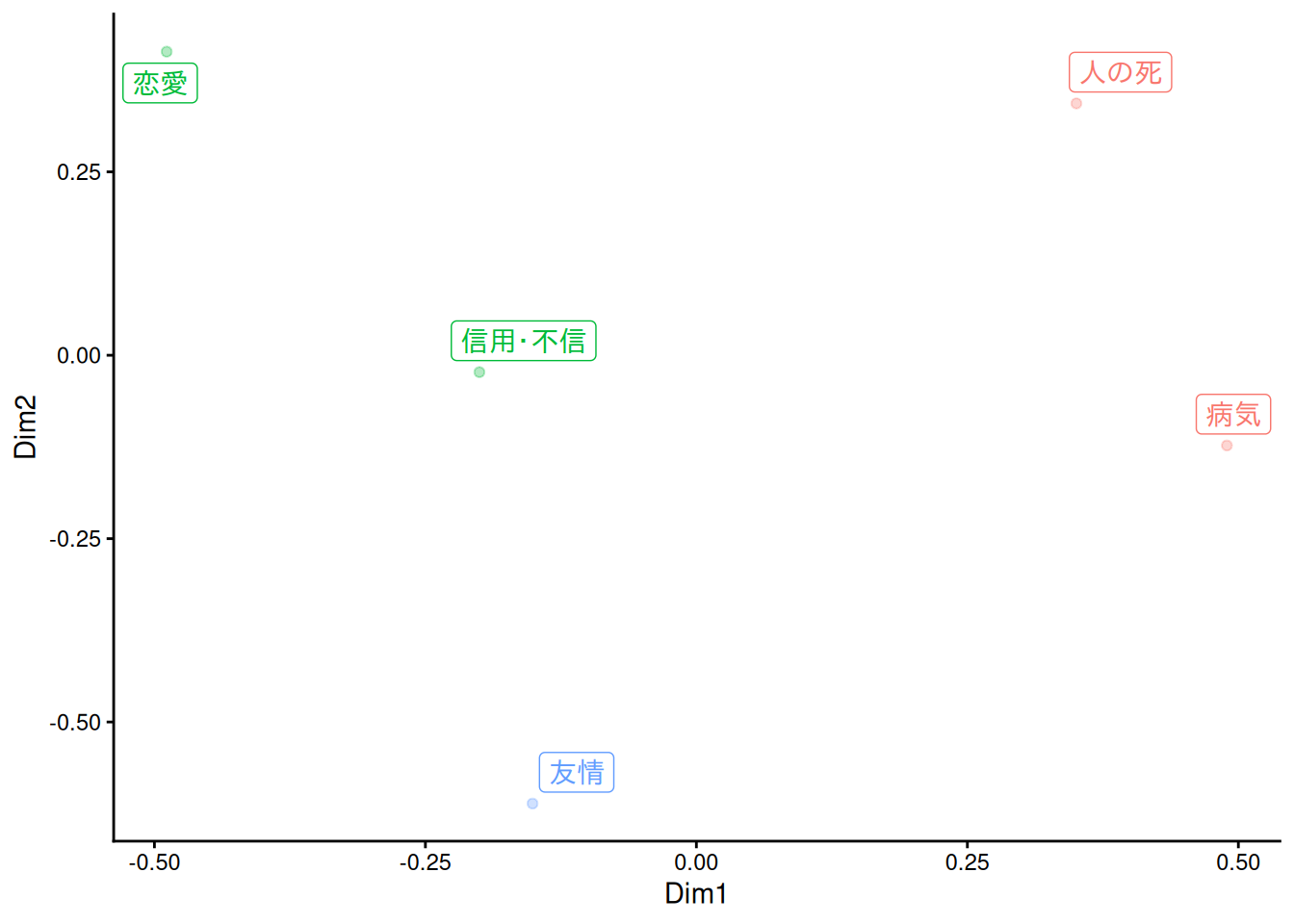
F.4.3 LSS🍳
極性をあらわす少数の種語を使いつつ、指定した語と共起する語や文書について1次元の極性を与える手法だそうです。LSXというパッケージとして実装されています。
本来はk(Truncated SVDにおけるランク)は200~300程度を指定するため、相当の量の文書が必要とされます。提案論文では、おおむね40文程度の長さの文書が5,000~10,000文書くらい必要と書かれています。ここでは分析にかける文書が足りていないので、意味を解釈できる結果は得られていないと思います。
rules <-
list(
"人の死" = c("死後", "死病", "死期", "死因", "死骸", "生死", "自殺", "殉死", "頓死", "変死", "亡", "死ぬ", "亡くなる", "殺す", "亡くす", "死"),
"恋愛" = c("愛", "恋", "愛す", "愛情", "恋人", "愛人", "恋愛", "失恋", "恋しい"),
"友情" = c("友達", "友人", "旧友", "親友", "朋友", "友", "級友"),
"信用・不信" = c("信用", "信じる", "信ずる", "不信", "疑い", "疑惑", "疑念", "猜疑", "狐疑", "疑問", "疑い深い", "疑う", "疑る", "警戒"),
"病気" = c("医者", "病人", "病室", "病院", "病症", "病状", "持病", "死病", "主治医", "精神病", "仮病", "病気", "看病", "大病", "病む", "病")
) |>
quanteda::dictionary()
# 日本語評価極性辞書(用言編) https://www.cl.ecei.tohoku.ac.jp/Open_Resources-Japanese_Sentiment_Polarity_Dictionary.html
pn <-
readr::read_tsv(
"https://www.cl.ecei.tohoku.ac.jp/resources/sent_lex/wago.121808.pn",
col_names = c("polarity", "word"),
show_col_types = FALSE
)
# 極性辞書をもとに種語を用意する
seed <- pn |>
dplyr::inner_join(
dplyr::tbl(con, "tokens") |>
dplyr::filter(pos == "動詞") |>
dplyr::select(token, pos, original) |>
dplyr::distinct() |>
dplyr::collect(),
by = c("word" = "token")
) |>
dplyr::mutate(
polarity = dplyr::if_else(
stringr::str_detect(polarity, "ネガ"),
"negative",
"positive"
),
token = dplyr::if_else(is.na(original), word, original),
token = paste(token, pos, sep = "/")
) |>
dplyr::distinct(polarity, token) |>
dplyr::reframe(dict = list(token), .by = polarity) |>
tibble::deframe()
seed <- seed |>
quanteda::dictionary() |>
LSX::as.seedwords(upper = 2, lower = 1) # ここではpositiveが2番目, negativeが1番目
#> Registered S3 methods overwritten by 'LSX':
#> method from
#> print.coefficients_textmodel quanteda.textmodels
#> print.statistics_textmodel quanteda.textmodels
#> print.summary.textmodel quanteda.textmodels
toks <-
dplyr::tbl(con, "tokens") |>
dplyr::filter(
pos %in% c(
"名詞", "名詞C",
"地名", "人名", "組織名", "固有名詞",
"動詞", "未知語", "タグ"
)
) |>
dplyr::mutate(
token = dplyr::if_else(is.na(original), token, original),
token = paste(token, pos, sep = "/")
) |>
dplyr::select(label, token) |>
dplyr::collect() |>
dplyr::reframe(dict = list(token), .by = label) |>
tibble::deframe() |>
quanteda::as.tokens()
term <-
LSX::char_context(
toks,
pattern = rules$`信用・不信`,
window = 10,
valuetype = "regex",
case_insensitive = FALSE,
min_count = 2,
p = 0.05
) |>
toupper()lss <-
LSX::textmodel_lss(
quanteda::dfm(toks),
seeds = seed,
terms = term,
k = 20,
include_data = TRUE,
group_data = TRUE
)単語の極性です。
LSX::textplot_terms(lss)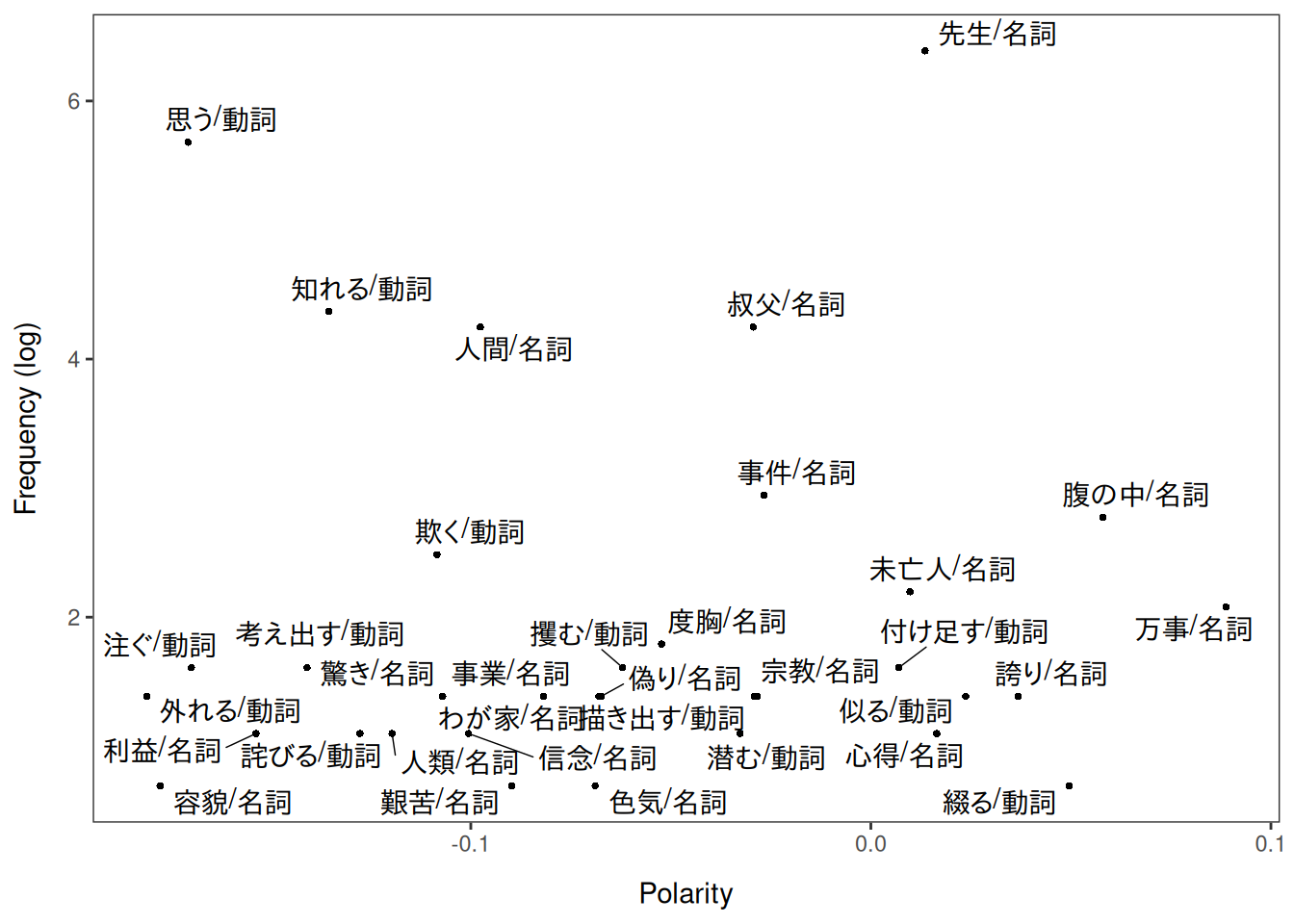
文書の極性です。ここでは文書の数が少ないのでこのようにプロットしていますが、実際にはもっと大量の文書を分析にかけるはずなので、文書を横軸にとってpolarityの曲線を描く可視化例がパッケージのvignetteで紹介されています。
tibble::tibble(
docs = factor(unique(tbl$label), levels = unique(tbl$label)),
polarity = predict(lss)[as.character(docs)],
section = tbl$section[match(docs, tbl$label)]
) |>
dplyr::filter(!is.na(polarity)) |>
ggplot(aes(x = docs, y = polarity, fill = section)) +
geom_bar(stat = "identity", show.legend = FALSE) +
coord_flip() +
theme_bw()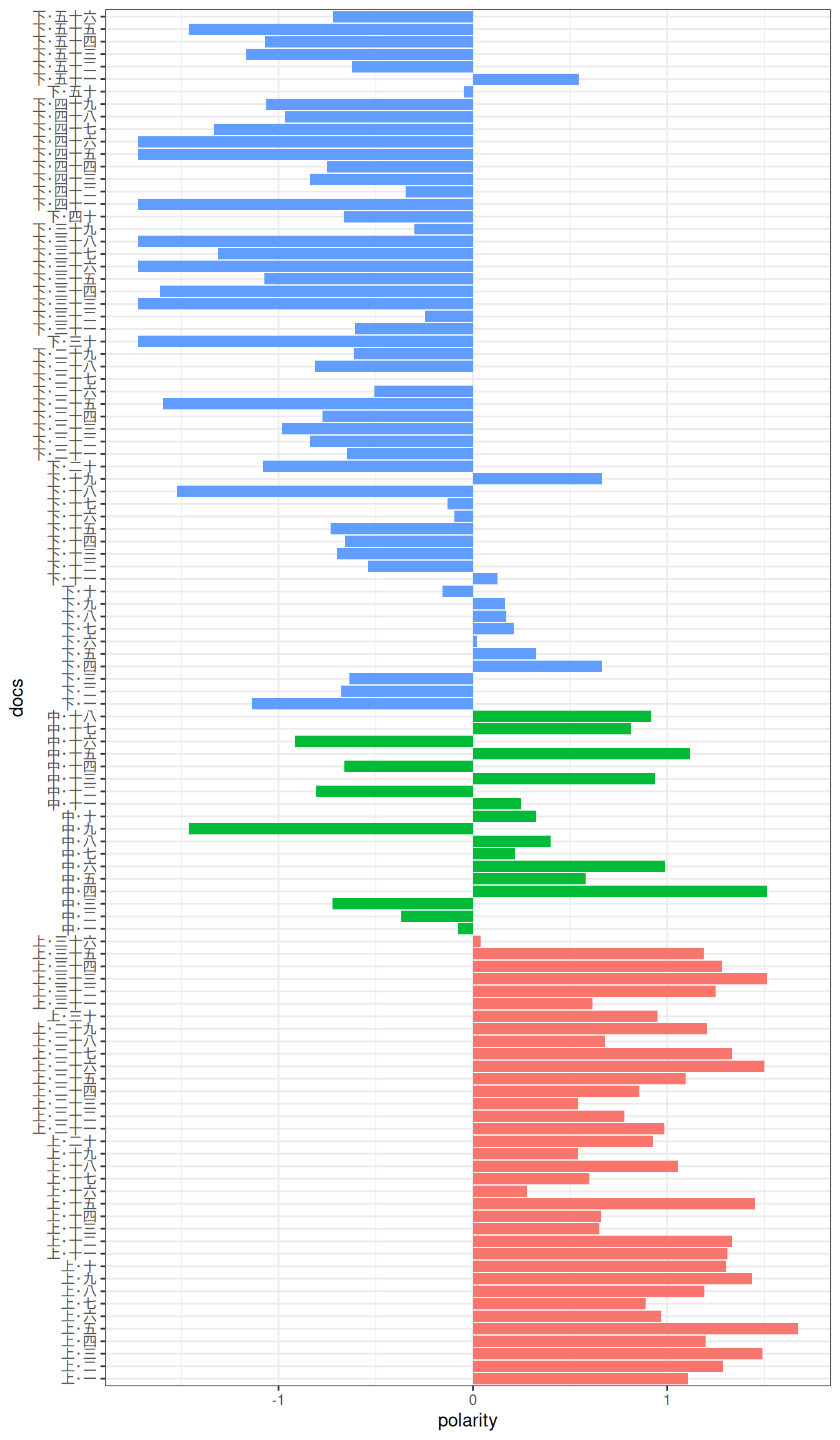
duckdb::dbDisconnect(con)
duckdb::duckdb_shutdown(drv)
sessioninfo::session_info(info = "packages")
#> ═ Session info ═══════════════════════════════════════════════════════════════
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date (UTC) lib source
#> abind 1.4-8 2024-09-12 [1] RSPM (R 4.5.0)
#> askpass 1.2.1 2024-10-04 [1] RSPM
#> audubon 0.6.2 2026-01-09 [1] RSPM (R 4.5.0)
#> backports 1.5.0 2024-05-23 [1] RSPM
#> bit 4.6.0 2025-03-06 [1] RSPM (R 4.5.0)
#> bit64 4.6.0-1 2025-01-16 [1] RSPM (R 4.5.0)
#> blob 1.3.0 2026-01-14 [1] RSPM (R 4.5.0)
#> broom 1.0.12 2026-01-27 [1] RSPM (R 4.5.0)
#> ca * 0.71.1 2020-01-24 [1] RSPM (R 4.5.0)
#> car 3.1-5 2026-02-03 [1] RSPM (R 4.5.0)
#> carData 3.0-6 2026-01-30 [1] RSPM (R 4.5.0)
#> cellranger 1.1.0 2016-07-27 [1] RSPM (R 4.5.0)
#> checkmate 2.3.4 2026-02-03 [1] RSPM (R 4.5.0)
#> cli 3.6.5 2025-04-23 [1] RSPM
#> codetools 0.2-20 2024-03-31 [2] CRAN (R 4.5.3)
#> crayon 1.5.3 2024-06-20 [1] RSPM
#> crosstable 0.9.0 2026-03-15 [1] RSPM (R 4.5.0)
#> curl 7.0.0 2025-08-19 [1] RSPM
#> data.table 1.18.2.1 2026-01-27 [1] RSPM (R 4.5.0)
#> DBI * 1.3.0 2026-02-25 [1] RSPM (R 4.5.0)
#> dbplyr 2.5.2 2026-02-13 [1] RSPM (R 4.5.0)
#> digest 0.6.39 2025-11-19 [1] RSPM
#> dplyr 1.2.0 2026-02-03 [1] RSPM (R 4.5.0)
#> duckdb * 1.5.0 2026-03-14 [1] RSPM (R 4.5.0)
#> evaluate 1.0.5 2025-08-27 [1] RSPM
#> farver 2.1.2 2024-05-13 [1] RSPM (R 4.5.0)
#> fastmap 1.2.0 2024-05-15 [1] RSPM
#> fastmatch 1.1-8 2026-01-17 [1] RSPM (R 4.5.0)
#> flextable 0.9.11 2026-02-13 [1] RSPM (R 4.5.0)
#> fontBitstreamVera 0.1.1 2017-02-01 [1] RSPM (R 4.5.0)
#> fontLiberation 0.1.0 2016-10-15 [1] RSPM (R 4.5.0)
#> fontquiver 0.2.1 2017-02-01 [1] RSPM (R 4.5.0)
#> forcats 1.0.1 2025-09-25 [1] RSPM (R 4.5.0)
#> foreach 1.5.2 2022-02-02 [1] RSPM (R 4.5.0)
#> Formula 1.2-5 2023-02-24 [1] RSPM (R 4.5.0)
#> gdtools 0.5.0 2026-02-09 [1] RSPM (R 4.5.0)
#> generics 0.1.4 2025-05-09 [1] RSPM (R 4.5.0)
#> ggplot2 * 4.0.2 2026-02-03 [1] RSPM (R 4.5.0)
#> ggpubr 0.6.3 2026-02-24 [1] RSPM (R 4.5.0)
#> ggrepel 0.9.8 2026-03-17 [1] RSPM (R 4.5.0)
#> ggsignif 0.6.4 2022-10-13 [1] RSPM (R 4.5.0)
#> gibasa 1.1.3 2026-03-24 [1] Github (paithiov909/gibasa@4d450d2)
#> glmnet 4.1-10 2025-07-17 [1] RSPM (R 4.5.0)
#> glue 1.8.0 2024-09-30 [1] RSPM
#> gtable 0.3.6 2024-10-25 [1] RSPM (R 4.5.0)
#> hms 1.1.4 2025-10-17 [1] RSPM (R 4.5.0)
#> htmltools 0.5.9 2025-12-04 [1] RSPM
#> htmlwidgets 1.6.4 2023-12-06 [1] RSPM
#> iterators 1.0.14 2022-02-05 [1] RSPM (R 4.5.0)
#> janeaustenr 1.0.0 2022-08-26 [1] RSPM (R 4.5.0)
#> jsonlite 2.0.0 2025-03-27 [1] RSPM
#> knitr 1.51 2025-12-20 [1] RSPM
#> labeling 0.4.3 2023-08-29 [1] RSPM (R 4.5.0)
#> lattice 0.22-9 2026-02-09 [2] CRAN (R 4.5.3)
#> legendry 0.2.4 2025-09-14 [1] RSPM (R 4.5.0)
#> lifecycle 1.0.5 2026-01-08 [1] RSPM
#> locfit 1.5-9.12 2025-03-05 [1] RSPM (R 4.5.0)
#> LSX 1.5.1 2025-12-09 [1] RSPM (R 4.5.0)
#> magrittr 2.0.4 2025-09-12 [1] RSPM
#> Matrix 1.7-4 2025-08-28 [2] CRAN (R 4.5.3)
#> nsyllable 1.0.1 2022-02-28 [1] RSPM (R 4.5.0)
#> officer 0.7.3 2026-01-16 [1] RSPM (R 4.5.0)
#> openssl 2.3.5 2026-02-26 [1] RSPM
#> otel 0.2.0 2025-08-29 [1] RSPM
#> patchwork 1.3.2 2025-08-25 [1] RSPM (R 4.5.0)
#> pillar 1.11.1 2025-09-17 [1] RSPM
#> pkgconfig 2.0.3 2019-09-22 [1] RSPM
#> proxyC 0.5.2 2025-04-25 [1] RSPM (R 4.5.0)
#> purrr 1.2.1 2026-01-09 [1] RSPM
#> quanteda 4.3.1 2025-07-10 [1] RSPM (R 4.5.0)
#> quanteda.textmodels 0.9.10 2025-02-10 [1] RSPM (R 4.5.0)
#> quanteda.textstats 0.97.2 2024-09-03 [1] RSPM (R 4.5.0)
#> R.cache 0.17.0 2025-05-02 [1] RSPM
#> R.methodsS3 1.8.2 2022-06-13 [1] RSPM
#> R.oo 1.27.1 2025-05-02 [1] RSPM
#> R.utils 2.13.0 2025-02-24 [1] RSPM
#> R6 2.6.1 2025-02-15 [1] RSPM
#> ragg 1.5.2 2026-03-23 [1] RSPM (R 4.5.0)
#> RColorBrewer 1.1-3 2022-04-03 [1] RSPM (R 4.5.0)
#> Rcpp 1.1.1 2026-01-10 [1] RSPM
#> RcppParallel 5.1.11-2 2026-03-05 [1] RSPM (R 4.5.0)
#> readr 2.2.0 2026-02-19 [1] RSPM (R 4.5.0)
#> readxl 1.4.5 2025-03-07 [1] RSPM (R 4.5.0)
#> rlang 1.1.7 2026-01-09 [1] RSPM
#> rmarkdown 2.30 2025-09-28 [1] RSPM
#> RSpectra 0.16-2 2024-07-18 [1] RSPM (R 4.5.0)
#> rstatix 0.7.3 2025-10-18 [1] RSPM (R 4.5.0)
#> S7 0.2.1 2025-11-14 [1] RSPM (R 4.5.0)
#> scales 1.4.0 2025-04-24 [1] RSPM (R 4.5.0)
#> sessioninfo 1.2.3 2025-02-05 [1] RSPM
#> shape 1.4.6.1 2024-02-23 [1] RSPM (R 4.5.0)
#> SnowballC 0.7.1 2023-04-25 [1] RSPM (R 4.5.0)
#> stopwords 2.3 2021-10-28 [1] RSPM (R 4.5.0)
#> stringi 1.8.7 2025-03-27 [1] RSPM
#> stringr 1.6.0 2025-11-04 [1] RSPM
#> styler 1.11.0 2025-10-13 [1] RSPM
#> survival 3.8-6 2026-01-16 [2] CRAN (R 4.5.3)
#> systemfonts 1.3.2 2026-03-05 [1] RSPM
#> textshaping 1.0.5 2026-03-06 [1] RSPM
#> tibble 3.3.1 2026-01-11 [1] RSPM
#> tidyr 1.3.2 2025-12-19 [1] RSPM (R 4.5.0)
#> tidyselect 1.2.1 2024-03-11 [1] RSPM (R 4.5.0)
#> tidytext 0.4.3 2025-07-25 [1] RSPM (R 4.5.0)
#> tokenizers 0.3.0 2022-12-22 [1] RSPM (R 4.5.0)
#> tzdb 0.5.0 2025-03-15 [1] RSPM (R 4.5.0)
#> utf8 1.2.6 2025-06-08 [1] RSPM
#> uuid 1.2-2 2026-01-23 [1] RSPM (R 4.5.0)
#> V8 8.0.1 2025-10-10 [1] RSPM (R 4.5.0)
#> vctrs 0.7.2 2026-03-21 [1] RSPM (R 4.5.0)
#> vroom 1.7.0 2026-01-27 [1] RSPM (R 4.5.0)
#> withr 3.0.2 2024-10-28 [1] RSPM
#> xfun 0.57 2026-03-20 [1] RSPM (R 4.5.0)
#> xml2 1.5.2 2026-01-17 [1] RSPM
#> yaml 2.3.12 2025-12-10 [1] RSPM
#> zip 2.3.3 2025-05-13 [1] RSPM
#>
#> [1] /usr/local/lib/R/site-library
#> [2] /usr/local/lib/R/library
#> * ── Packages attached to the search path.
#>
#> ──────────────────────────────────────────────────────────────────────────────