suppressPackageStartupMessages({
library(ggplot2)
library(duckdb)
})
drv <- duckdb::duckdb()
con <- duckdb::dbConnect(drv, dbdir = "tutorial_jp/kokoro.duckdb", read_only = TRUE)
tbl <-
readxl::read_xls("tutorial_jp/kokoro.xls",
col_names = c("text", "section", "chapter", "label"),
skip = 1
) |>
dplyr::mutate(
doc_id = factor(dplyr::row_number()),
dplyr::across(where(is.character), ~ audubon::strj_normalize(.))
) |>
dplyr::filter(!gibasa::is_blank(text)) |>
dplyr::relocate(doc_id, text, section, label, chapter)Appendix E — 文書メニュー
E.1 文書検索(A.6.1)
E.1.1 TF-IDF
KWICの結果を検索語のTF-IDFの降順で並び替える例です。
dat <-
dplyr::tbl(con, "tokens") |>
dplyr::filter(section == "[1]上_先生と私") |>
dplyr::select(label, token) |>
dplyr::collect()
dat |>
dplyr::reframe(token = list(token), .by = label) |>
tibble::deframe() |>
quanteda::as.tokens() |>
quanteda::tokens_select("[[:punct:]]", selection = "remove", valuetype = "regex", padding = FALSE) |>
quanteda::kwic(pattern = "^向[いくけこ]$", window = 5, valuetype = "regex") |>
dplyr::as_tibble() |>
dplyr::select(docname, pre, keyword, post) |>
dplyr::left_join(
dat |>
dplyr::count(label, token) |>
tidytext::bind_tf_idf(token, label, n),
by = dplyr::join_by(docname == label, keyword == token)
) |>
dplyr::arrange(desc(tf_idf))
#> # A tibble: 18 × 8
#> docname pre keyword post n tf idf tf_idf
#> <chr> <chr> <chr> <chr> <int> <dbl> <dbl> <dbl>
#> 1 上・三十四 いっ た なり 下 を 向い た 私 … 2 0.00251 1.19 0.00298
#> 2 上・三十四 突然 奥さん の 方 を 向い た 静 … 2 0.00251 1.19 0.00298
#> 3 上・八 は 私 の 方 を 向い て いっ… 2 0.00239 1.19 0.00283
#> 4 上・八 また 私 の 方 を 向い た 子供… 2 0.00239 1.19 0.00283
#> 5 上・二 て 海 の 方 を 向い て 立っ… 2 0.00217 1.19 0.00257
#> 6 上・二 まで 沖 の 方 へ 向い て 行っ… 2 0.00217 1.19 0.00257
#> 7 上・十二 な 方角 へ 足 を 向け た それ… 1 0.00117 2.20 0.00257
#> 8 上・十六 の 眼 を 私 に 向け た そう… 1 0.00117 2.20 0.00256
#> 9 上・三十三 先生 は ちょっと 顔 だけ 向け 直し て… 1 0.00112 2.20 0.00246
#> 10 上・二十五 た 世間 に 背中 を 向け た 人 … 1 0.00107 2.20 0.00236
#> 11 上・十七 う 世の中 の どっち を 向い て も … 1 0.00122 1.19 0.00145
#> 12 上・十二 花 より も そちら を 向い て 眼 … 1 0.00117 1.19 0.00139
#> 13 上・七 は 外 の 方 を 向い て 今 … 1 0.00116 1.19 0.00138
#> 14 上・十四 に 庭 の 方 を 向い た その… 1 0.00115 1.19 0.00137
#> 15 上・三十三 は 庭 の 方 を 向い て 澄ま… 1 0.00112 1.19 0.00133
#> 16 上・三十五 は 庭 の 方 を 向い て 笑っ… 1 0.00110 1.19 0.00131
#> 17 上・十五 は また 奥さん と 差し 向い で 話 … 1 0.00109 1.19 0.00129
#> 18 上・二十六 を し て よそ を 向い て 歩い… 1 0.00106 1.19 0.00126E.1.2 LexRank🍳
LexRankは、TF-IDFで重みづけした文書間の類似度行列についてページランクを計算することで、文書集合のなかから「重要な文書」を抽出する手法です。
dat <-
dplyr::tbl(con, "tokens") |>
dplyr::filter(
pos %in% c(
"名詞", # "名詞B", "名詞C",
"地名", "人名", "組織名", "固有名詞",
"動詞", "未知語", "タグ"
)
) |>
dplyr::mutate(
token = dplyr::if_else(is.na(original), token, original),
token = paste(token, pos, sep = "/")
)
dfm <- dat |>
dplyr::count(label, token) |>
dplyr::collect() |>
tidytext::bind_tf_idf(token, label, n) |>
dplyr::inner_join(
dat |>
dplyr::select(doc_id, label, token) |>
dplyr::collect(),
by = dplyr::join_by(label == label, token == token)
) |>
tidytext::cast_dfm(doc_id, token, tf_idf)文書間のコサイン類似度を得て、PageRankを計算します。quanteda.textstats::textstat_simil()はproxyC::simil()と処理としては同じですが、戻り値がtextstat_simil_symm_sparseというS4クラスのオブジェクトになっていて、as.data.frame()で縦長のデータフレームに変換できます。
scores <- dfm |>
quanteda.textstats::textstat_simil(
margin = "documents",
method = "cosine",
min_simil = .6 # LexRankの文脈でいうところのthreshold
) |>
as.data.frame() |>
dplyr::mutate(weight = 1) |> # 閾値以上のエッジしかないので、重みはすべて1にする
# dplyr::rename(weight = cosine) |> # あるいは、閾値を指定せずに、コサイン類似度をそのまま重みとして使う(continuous LexRank)
igraph::graph_from_data_frame(directed = FALSE) |>
igraph::page_rank(directed = FALSE, damping = .85) |>
purrr::pluck("vector")LexRankは抽出型の要約アルゴリズムということになっていますが、必ずしも要約的な文書が得られるわけではありません。文書集合のなかでも類似度が比較的高そうな文書をn件取り出してきてサブセットをつくるみたいな使い方ならできるかもしれないです。
sort(scores, decreasing = TRUE) |>
tibble::enframe() |>
dplyr::left_join(
dplyr::select(tbl, doc_id, text, chapter),
by = dplyr::join_by(name == doc_id)
) |>
dplyr::slice_head(n = 5)
#> # A tibble: 5 × 4
#> name value text chapter
#> <chr> <dbl> <chr> <chr>
#> 1 1123 0.00702 「馬鹿だ」とやがてKが答えました。「僕は馬鹿だ」 3_41
#> 2 1027 0.00490 私はKに手紙を見せました。Kは何ともいいませんでしたけれども、自分の所へこの姉から同じような意味の書状が二、三… 3_22
#> 3 1025 0.00461 「Kの事件が一段落ついた後で、私は彼の姉の夫から長い封書を受け取りました。Kの養子に行った先は、この人の親類に… 3_22
#> 4 1122 0.00461 私は二度同じ言葉を繰り返しました。そうして、その言葉がKの上にどう影響するかを見詰めていました。…… 3_41
#> 5 1028 0.00382 私はKと同じような返事を彼の義兄宛で出しました。その中に、万一の場合には私がどうでもするから、安心するようにと… 3_22E.2 クラスター分析(A.6.2)
E.2.1 LSI🍳
文書単語行列(または、単語文書行列)に対して特異値分解をおこなって、行列の次元を削減する手法をLSIといいます。潜在的意味インデキシング(Latent Semantic Indexing, LSI)というのは情報検索の分野での呼び方で、自然言語処理の文脈だと潜在意味解析(Latent Semantic Analysis, LSA)というらしいです。
dfm <-
dplyr::tbl(con, "tokens") |>
dplyr::filter(
pos %in% c(
"名詞", "名詞B", "名詞C",
"地名", "人名", "組織名", "固有名詞",
"動詞", "未知語", "タグ"
)
) |>
dplyr::mutate(
token = dplyr::if_else(is.na(original), token, original),
token = paste(token, pos, sep = "/")
) |>
dplyr::count(doc_id, token) |>
dplyr::collect() |>
tidytext::cast_dfm(doc_id, token, n) |>
quanteda::dfm_trim(min_termfreq = 10) |>
quanteda::dfm_tfidf(scheme_tf = "prop") |>
rlang::as_function(
~ quanteda::dfm_subset(., quanteda::rowSums(.) > 0)
)()
dfm
#> Document-feature matrix of: 1,099 documents, 332 features (97.22% sparse) and 0 docvars.
#> features
#> docs 先生/名詞 帰る/動詞 断る/動詞 一人/タグ 大分/地名 通り抜ける/動詞
#> 2 0.01676422 0.11890869 0.0517327 0.03707651 0 0
#> 3 0 0.06738159 0 0.08404009 0.1275876 0
#> 4 0 0 0 0 0 0
#> 5 0 0 0 0.07003341 0 0.1144412
#> 6 0.03799889 0 0 0 0 0
#> 7 0.14249585 0 0 0.06303007 0 0
#> features
#> docs 来る/動詞 間/名詞C 頭/名詞C 隠す/動詞
#> 2 0.05726953 0 0 0
#> 3 0 0 0 0
#> 4 0 0 0 0
#> 5 0.05408789 0.06550713 0.06854817 0
#> 6 0 0.07860855 0 0
#> 7 0 0.05895641 0.12338671 0
#> [ reached max_ndoc ... 1,093 more documents, reached max_nfeat ... 322 more features ]ここでは300列くらいしかないので大したことないですが、特徴量の数が多い文書単語行列をas.matrix()すると、メモリ上でのサイズが大きいオブジェクトになってしまい、扱いづらいです。そこで、もとの文書単語行列のもつ情報をできるだけ保持しつつ、行列の次元を削減したいというときに、LSIを利用することができます。
とくに、文書のクラスタリングをおこなう場合では、どの語彙がどのクラスタに属する要因になっているかみたいなことはどうせ確認できないので、特徴量は適当に削減してしまって問題ないと思います。
lobstr::obj_size(dfm)
#> 244.78 kB
lobstr::obj_size(as.matrix(dfm))
#> 3.02 MBquanteda:textmodels::textmodel_lsa(margin = "documents")とすると、特異値分解(Truncated SVD)の \(D \simeq D_{k} = U_{k}\Sigma{}_{k}V^{T}_{k}\) という式における \(V_{k}\) が戻り値にそのまま残ります(margin="features"だと \(U_{k}\) がそのまま残り、"both"で両方ともそのまま残ります)。
特異値分解する行列 \(D\) について、いま、行側に文書・列側に単語がある持ち方をしています。ここでは、行列 \(D\) をランク \(k\) の行列 \(D_{k}\) で近似したい(ランク削減したい)というより、特徴量を減らしたい( \(k\) 列の行列にしてしまいたい)と思っているため、dfmに \(V_{k}\) をかけます。
mat <- quanteda.textmodels::textmodel_lsa(dfm, nd = 50, margin = "documents")
mat <- dfm %*% mat$features
str(mat)
#> Formal class 'dgeMatrix' [package "Matrix"] with 4 slots
#> ..@ Dim : int [1:2] 1099 50
#> ..@ Dimnames:List of 2
#> .. ..$ docs: chr [1:1099] "2" "3" "4" "5" ...
#> .. ..$ : NULL
#> ..@ x : num [1:54950] -0.0512 -0.0259 -0.0294 -0.0372 -0.0577 ...
#> ..@ factors : list()E.2.2 階層的クラスタリング
LSIで次元を削減した行列について、クラスタリングをおこないます。ここでは、文書間の距離としてコサイン距離を使うことにします。
文書間の距離のイメージです。
g1 <- mat |>
proxyC::simil(margin = 1, method = "ejaccard") |>
rlang::as_function(~ 1 - .[1:100, 1:100])() |>
as.dist() |>
factoextra::fviz_dist() +
theme(axis.text.x = element_blank(), axis.text.y = element_blank()) +
labs(title = "ejaccard")
g2 <- mat |>
proxyC::simil(margin = 1, method = "edice") |>
rlang::as_function(~ 1 - .[1:100, 1:100])() |>
as.dist() |>
factoextra::fviz_dist() +
theme(axis.text.x = element_blank(), axis.text.y = element_blank()) +
labs(title = "edice")
g3 <- mat |>
proxyC::simil(margin = 1, method = "cosine") |>
rlang::as_function(~ 1 - .[1:100, 1:100])() |>
as.dist() |>
factoextra::fviz_dist() +
theme(axis.text.x = element_blank(), axis.text.y = element_blank()) +
labs(title = "cosine")
patchwork::wrap_plots(g1, g2, g3, nrow = 3)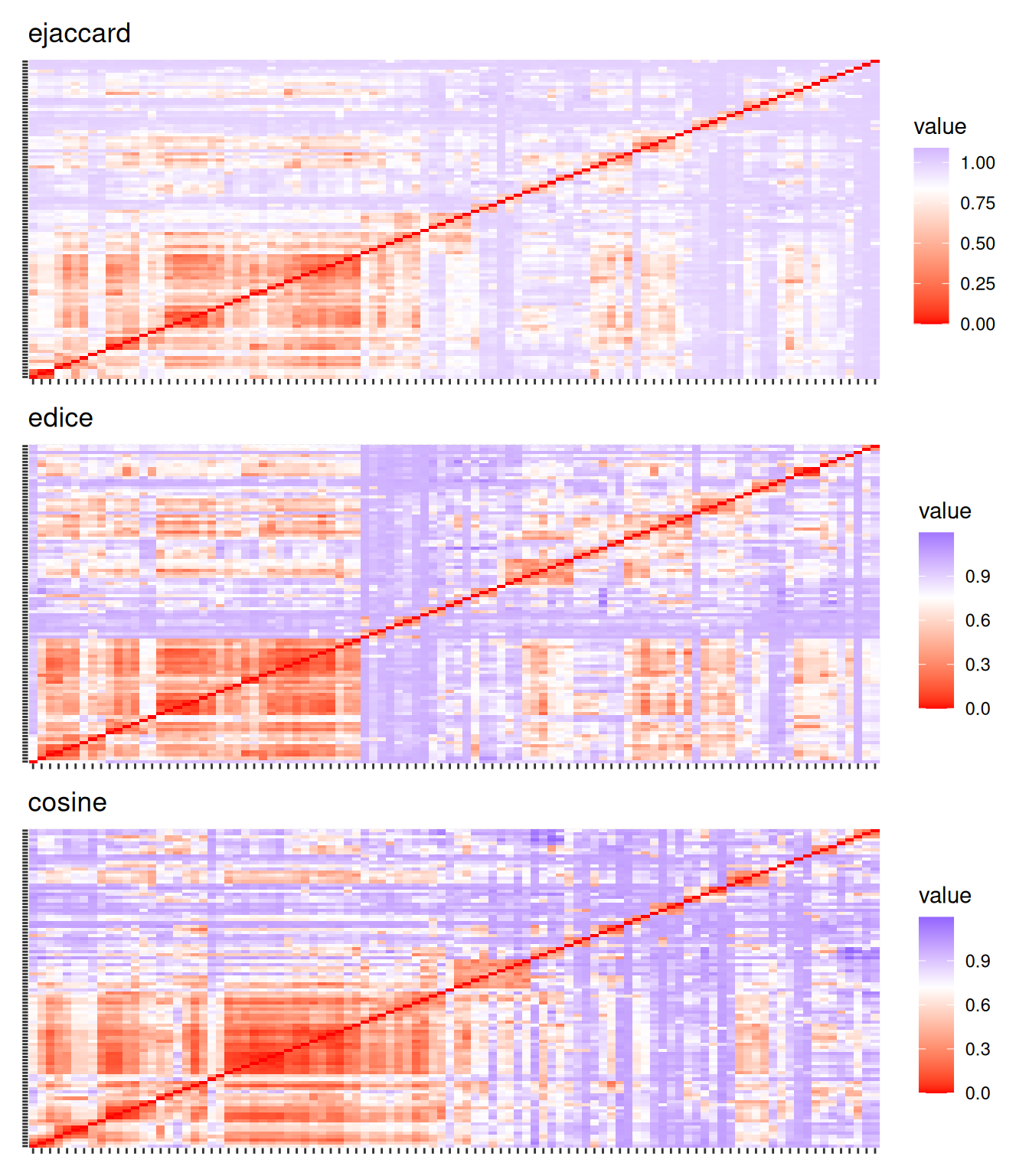
階層的クラスタリングは非階層的なアルゴリズムに比べると計算量が多いため、個体数が増えるとクラスタリングするのにやや時間がかかることがあります。
dat <- mat |>
proxyC::simil(margin = 1, method = "cosine") |>
rlang::as_function(~ 1 - .)()
clusters <-
as.dist(dat) |>
hclust(method = "ward.D2")
cluster::silhouette(cutree(clusters, k = 5), dist = dat) |>
factoextra::fviz_silhouette(print.summary = FALSE) +
theme_classic() +
theme(axis.text.x = element_blank())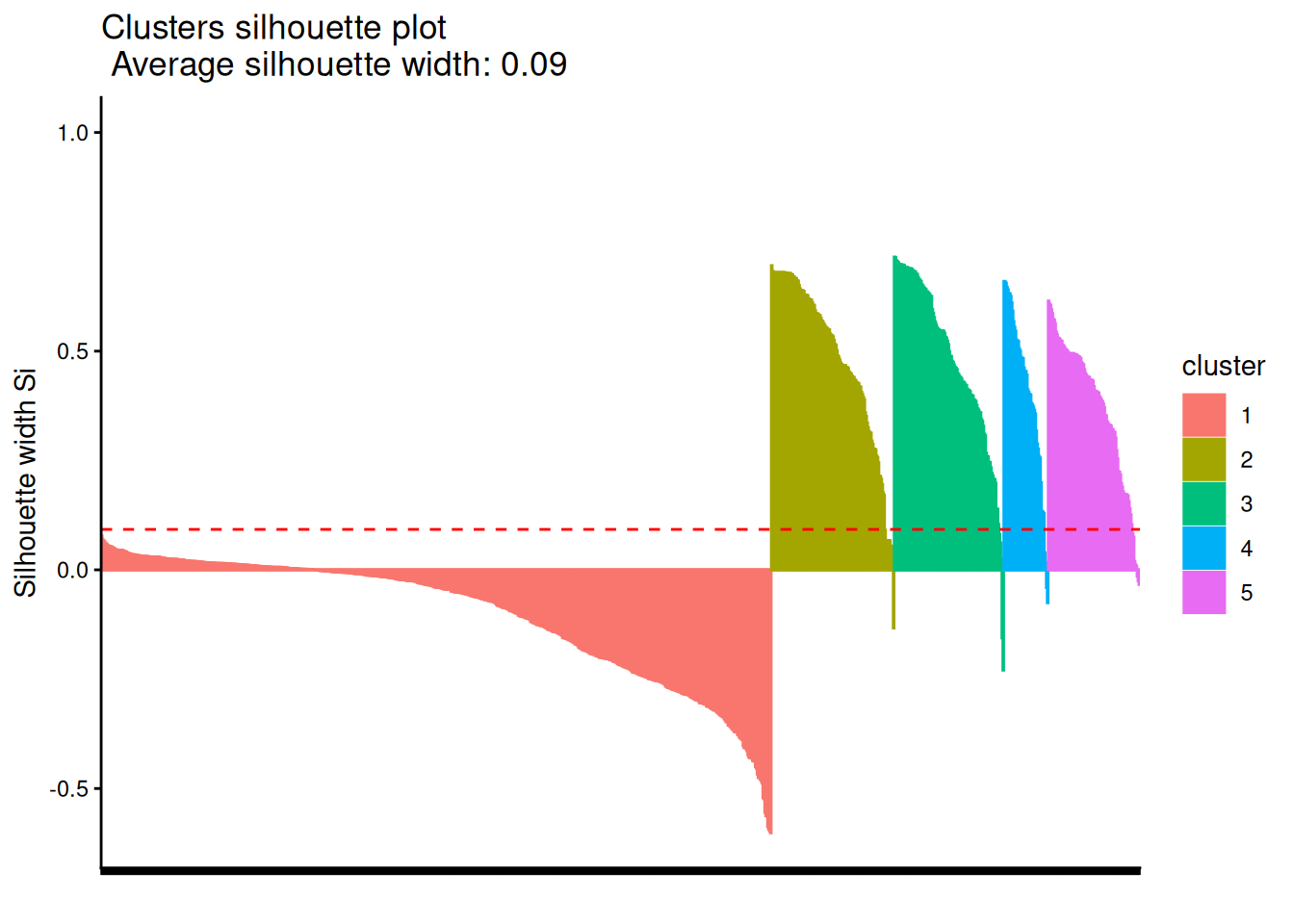
E.2.3 非階層的クラスタリング🍳
必ずしもクラスタの階層構造を確認したいわけではない場合、kmeans()だと計算が高速かもしれません。
ただ、「K-meansはクラスタ中心からのユークリッド距離でクラスタを分ける」(機械学習帳)ため、特徴量の数が増えてくるとクラスタの比率がおかしくなりがちです。
clusters <- kmeans(mat, centers = 5, iter.max = 100, algorithm = "Lloyd")
cluster::silhouette(clusters$cluster, dist = dat) |>
factoextra::fviz_silhouette(print.summary = FALSE) +
theme_classic() +
theme(axis.text.x = element_blank())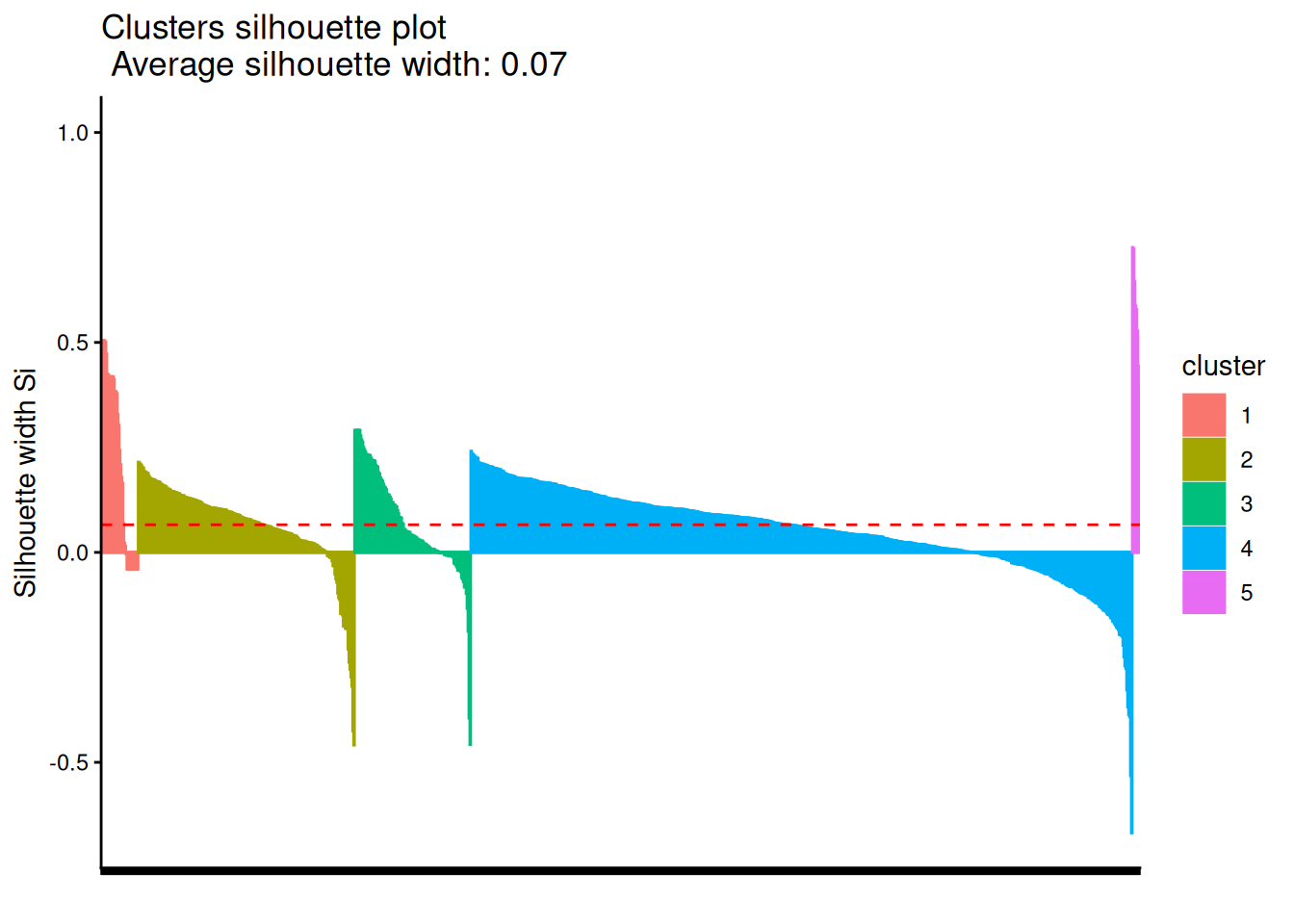
spherical k-meansの実装であるskmeansだとクラスタの比率はいくらかマシになるかもしれません。
clusters <-
skmeans::skmeans(
as.matrix(mat),
k = 5,
method = "pclust",
control = list(maxiter = 100)
)
cluster::silhouette(clusters$cluster, dist = dat) |>
factoextra::fviz_silhouette(print.summary = FALSE) +
theme_classic() +
theme(axis.text.x = element_blank())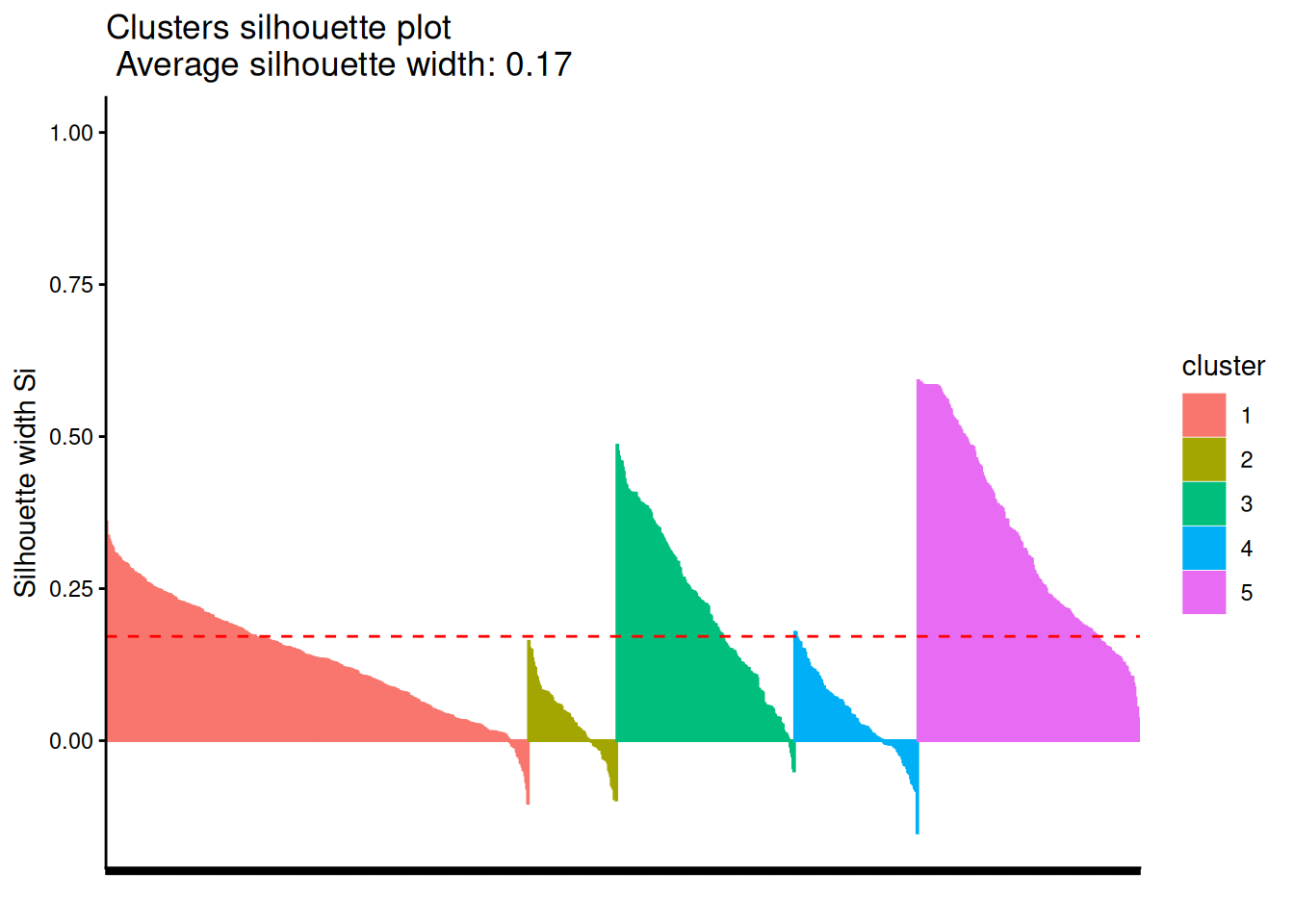
E.3 トピックモデル(A.6.3-4)
E.3.1 トピック数の探索
LDAのトピック数の探索は、実際にfitしてみて指標のよかったトピック数を採用するみたいなやり方をするようです。
dfm <-
dplyr::tbl(con, "tokens") |>
dplyr::filter(
pos %in% c(
"名詞", "名詞B", "名詞C",
"地名", "人名", "組織名", "固有名詞",
"動詞", "未知語", "タグ"
)
) |>
dplyr::mutate(
token = dplyr::if_else(is.na(original), token, original),
token = paste(token, pos, sep = "/")
) |>
dplyr::count(doc_id, token) |>
dplyr::collect() |>
tidytext::cast_dfm(doc_id, token, n)ここでは、トピック数を5から15まで変化させます。seededlda::textmodel_lda(auto_iter=TRUE)とすると、ステップがmax_iter以下であっても条件によってギブスサンプリングを打ち切る挙動になります。
divergence <-
purrr::map(5:15, \(.x) {
lda_fit <-
seededlda::textmodel_lda(dfm, k = .x, batch_size = 0.2, auto_iter = TRUE, verbose = FALSE)
tibble::tibble(
topics = .x,
Deveaud2014 = seededlda::divergence(lda_fit, regularize = FALSE),
WatanabeBaturo2023 = seededlda::divergence(lda_fit, min_size = .04, regularize = TRUE)
)
}) |>
purrr::list_rbind()Deveaud2014という列は、ldatuningで確認できる同名の値と同じ指標です。WatanabeBaturo2023という列は、Deveaud2014についてトピックの比率が閾値を下回るときにペナルティを加えるように修正した指標です。どちらも大きいほうがよい指標なので、基本的には値が大きくなっているトピック数を選びます。
ggplot(divergence, aes(topics)) +
geom_line(aes(y = Deveaud2014, color = "Deveaud2014")) +
geom_line(aes(y = WatanabeBaturo2023, color = "WatanabeBaturo2023")) +
scale_x_continuous(breaks = 5:15) +
theme_bw() +
ylab("Divergence")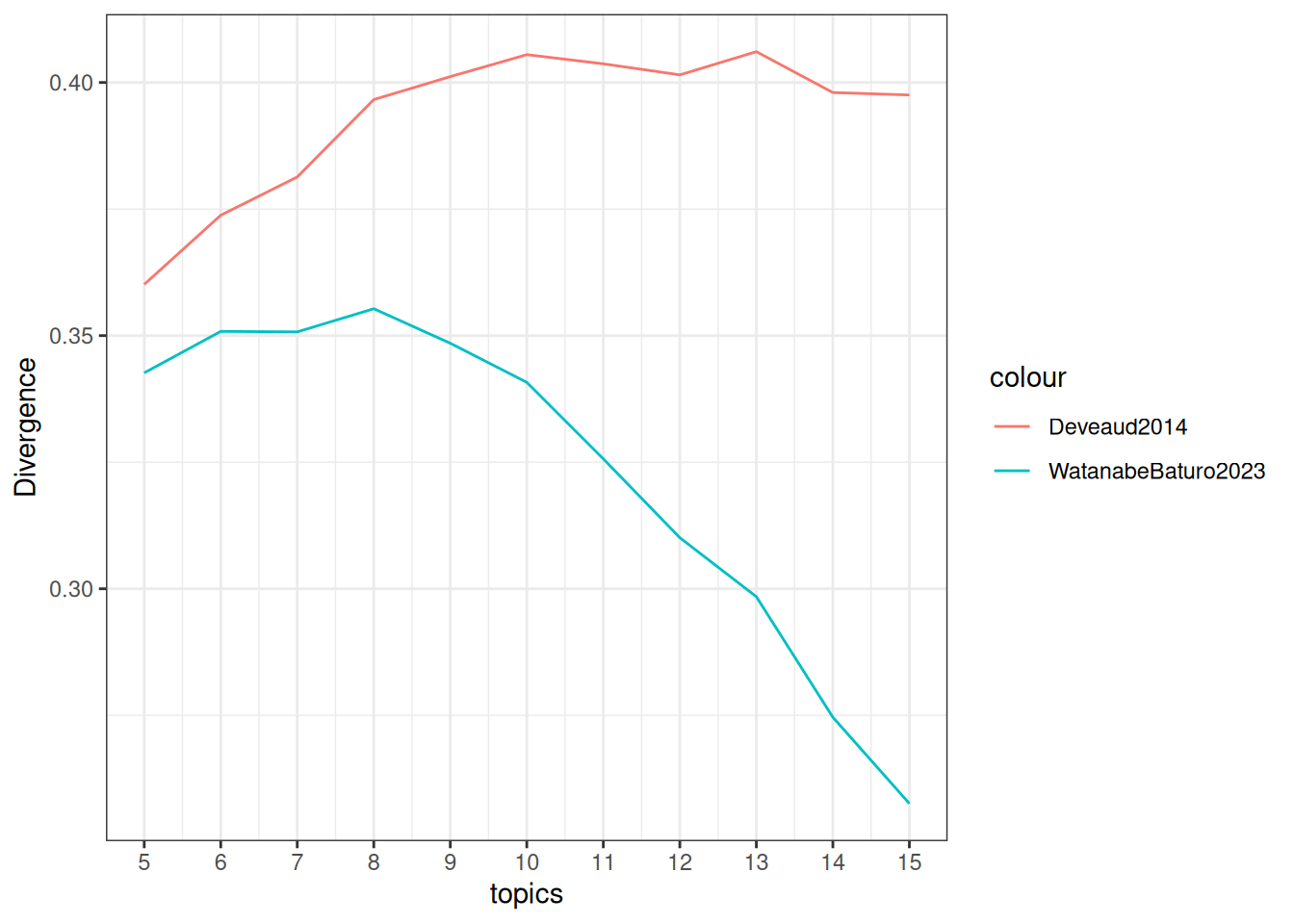
E.3.2 Distributed LDA
lda_fit <-
seededlda::textmodel_lda(dfm, k = 9, batch_size = 0.2, verbose = FALSE)
seededlda::sizes(lda_fit)
#> topic1 topic2 topic3 topic4 topic5 topic6 topic7
#> 0.11265899 0.10963053 0.09408439 0.13375732 0.12502524 0.11987684 0.10624874
#> topic8 topic9
#> 0.10004038 0.09867757E.3.3 トピックとその出現位置
dat <- tbl |>
dplyr::transmute(
doc_id = doc_id,
topic = seededlda::topics(lda_fit)[as.character(doc_id)],
) |>
dplyr::filter(!is.na(topic)) # dfmをつくった時点で単語を含まない文書はトピックの割り当てがないため、取り除く
dat |>
ggplot(aes(x = doc_id)) +
geom_raster(aes(y = topic, fill = topic), show.legend = FALSE) +
theme_classic() +
theme(axis.text.x = element_blank())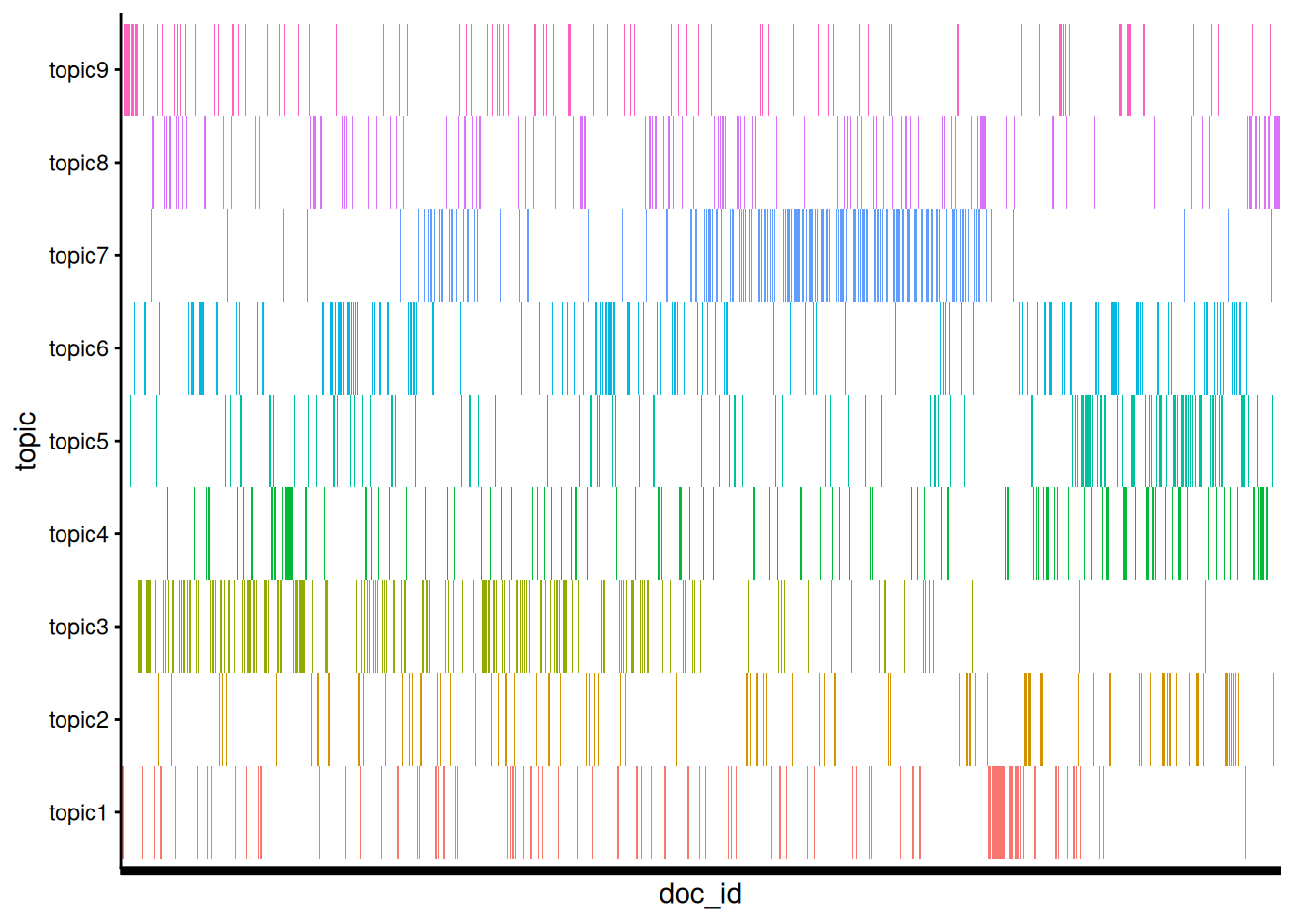
E.3.4 単語の生起確率
dat <-
t(lda_fit$phi) |>
dplyr::as_tibble(
.name_repair = ~ paste0("topic", seq_along(.)),
rownames = "word"
) |>
tidyr::pivot_longer(starts_with("topic"), names_to = "topic", values_to = "phi") |>
dplyr::mutate(phi = signif(phi, 3)) |>
dplyr::slice_max(phi, n = 20, by = topic)
reactable::reactable(
dat,
filterable = TRUE,
defaultColDef = reactable::colDef(
cell = reactablefmtr::data_bars(dat, text_position = "outside-base")
)
)E.4 ナイーブベイズ(A.6.6-8)
quanteda.textmodels::textmodel_nb()で分類する例です。ここでは、LexRankの節で抽出したscoresの付いている文書を使って学習します。交差検証はしません。
dfm <-
dplyr::tbl(con, "tokens") |>
dplyr::filter(
pos %in% c(
"名詞", # "名詞B", "名詞C",
"地名", "人名", "組織名", "固有名詞",
"動詞", "未知語", "タグ"
)
) |>
dplyr::mutate(
token = dplyr::if_else(is.na(original), token, original),
token = paste(token, pos, sep = "/")
) |>
dplyr::count(doc_id, token) |>
dplyr::collect() |>
tidytext::cast_dfm(doc_id, token, n) |>
quanteda::dfm_tfidf(scheme_tf = "prop")
labels <- tbl |>
dplyr::mutate(section = factor(section, labels = c("上", "中", "下"))) |>
dplyr::filter(doc_id %in% quanteda::docnames(dfm)) |>
dplyr::pull(section, doc_id)
nb_fit <- dfm |>
quanteda::dfm_subset(
quanteda::docnames(dfm) %in% names(scores)
) |>
rlang::as_function(~ {
# dfmに格納すると文書の順番が入れ替わるので、labelsの順番をあわせなければならない
quanteda.textmodels::textmodel_nb(., labels[quanteda::docnames(.)])
})()
dat <- tbl |>
dplyr::mutate(section = factor(section, labels = c("上", "中", "下"))) |>
dplyr::filter(doc_id %in% quanteda::docnames(dfm)) |>
dplyr::mutate(.pred = predict(nb_fit, dfm)[as.character(doc_id)]) # 予測値の順番をあわせる必要がある
yardstick::conf_mat(dat, section, .pred) # 混同行列
#> Truth
#> Prediction 上 中 下
#> 上 491 103 60
#> 中 43 140 11
#> 下 22 30 229
yardstick::accuracy(dat, section, .pred) # 正解率
#> # A tibble: 1 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 accuracy multiclass 0.762
yardstick::f_meas(dat, section, .pred) # F値
#> # A tibble: 1 × 3
#> .metric .estimator .estimate
#> <chr> <chr> <dbl>
#> 1 f_meas macro 0.733精度よく分類することよりも、各カテゴリにおける「スコア」を見るのが目的でナイーブベイズを使っているはずなので、確認してみます。
dat <-
coef(nb_fit) |>
dplyr::as_tibble(rownames = "token") |>
rlang::as_function(~ {
s <- t(coef(nb_fit)) |> colSums()
dplyr::mutate(.,
across(where(is.numeric), ~ . / s),
var = t(coef(nb_fit)) |> cov() |> diag(),
across(where(is.numeric), ~ signif(., 3))
)
})() |>
dplyr::slice_max(var, n = 50)
reactable::reactable(
dat,
filterable = TRUE,
defaultColDef = reactable::colDef(
cell = reactablefmtr::data_bars(dat, text_position = "outside-base")
)
)duckdb::dbDisconnect(con)
duckdb::duckdb_shutdown(drv)
sessioninfo::session_info(info = "packages")
#> ═ Session info ═══════════════════════════════════════════════════════════════
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date (UTC) lib source
#> abind 1.4-8 2024-09-12 [1] RSPM (R 4.5.0)
#> audubon 0.6.2 2026-01-09 [1] RSPM (R 4.5.0)
#> backports 1.5.0 2024-05-23 [1] RSPM
#> blob 1.3.0 2026-01-14 [1] RSPM (R 4.5.0)
#> broom 1.0.12 2026-01-27 [1] RSPM (R 4.5.0)
#> car 3.1-5 2026-02-03 [1] RSPM (R 4.5.0)
#> carData 3.0-6 2026-01-30 [1] RSPM (R 4.5.0)
#> cellranger 1.1.0 2016-07-27 [1] RSPM (R 4.5.0)
#> cli 3.6.5 2025-04-23 [1] RSPM
#> clue 0.3-67 2026-02-18 [1] RSPM (R 4.5.0)
#> cluster 2.1.8.2 2026-02-05 [2] CRAN (R 4.5.3)
#> codetools 0.2-20 2024-03-31 [2] CRAN (R 4.5.3)
#> crosstalk 1.2.2 2025-08-26 [1] RSPM (R 4.5.0)
#> curl 7.0.0 2025-08-19 [1] RSPM
#> DBI * 1.3.0 2026-02-25 [1] RSPM (R 4.5.0)
#> dbplyr 2.5.2 2026-02-13 [1] RSPM (R 4.5.0)
#> digest 0.6.39 2025-11-19 [1] RSPM
#> dplyr 1.2.0 2026-02-03 [1] RSPM (R 4.5.0)
#> duckdb * 1.5.0 2026-03-14 [1] RSPM (R 4.5.0)
#> evaluate 1.0.5 2025-08-27 [1] RSPM
#> factoextra 2.0.0 2026-03-03 [1] RSPM (R 4.5.0)
#> farver 2.1.2 2024-05-13 [1] RSPM (R 4.5.0)
#> fastmap 1.2.0 2024-05-15 [1] RSPM
#> fastmatch 1.1-8 2026-01-17 [1] RSPM (R 4.5.0)
#> foreach 1.5.2 2022-02-02 [1] RSPM (R 4.5.0)
#> Formula 1.2-5 2023-02-24 [1] RSPM (R 4.5.0)
#> generics 0.1.4 2025-05-09 [1] RSPM (R 4.5.0)
#> ggplot2 * 4.0.2 2026-02-03 [1] RSPM (R 4.5.0)
#> ggpubr 0.6.3 2026-02-24 [1] RSPM (R 4.5.0)
#> ggrepel 0.9.8 2026-03-17 [1] RSPM (R 4.5.0)
#> ggsignif 0.6.4 2022-10-13 [1] RSPM (R 4.5.0)
#> gibasa 1.1.3 2026-03-24 [1] Github (paithiov909/gibasa@4d450d2)
#> glmnet 4.1-10 2025-07-17 [1] RSPM (R 4.5.0)
#> glue 1.8.0 2024-09-30 [1] RSPM
#> gtable 0.3.6 2024-10-25 [1] RSPM (R 4.5.0)
#> htmltools 0.5.9 2025-12-04 [1] RSPM
#> htmlwidgets 1.6.4 2023-12-06 [1] RSPM
#> igraph 2.2.2 2026-02-12 [1] RSPM
#> iterators 1.0.14 2022-02-05 [1] RSPM (R 4.5.0)
#> janeaustenr 1.0.0 2022-08-26 [1] RSPM (R 4.5.0)
#> jsonlite 2.0.0 2025-03-27 [1] RSPM
#> knitr 1.51 2025-12-20 [1] RSPM
#> labeling 0.4.3 2023-08-29 [1] RSPM (R 4.5.0)
#> lattice 0.22-9 2026-02-09 [2] CRAN (R 4.5.3)
#> lifecycle 1.0.5 2026-01-08 [1] RSPM
#> lobstr 1.2.0 2026-02-18 [1] RSPM (R 4.5.0)
#> magrittr 2.0.4 2025-09-12 [1] RSPM
#> Matrix 1.7-4 2025-08-28 [2] CRAN (R 4.5.3)
#> nsyllable 1.0.1 2022-02-28 [1] RSPM (R 4.5.0)
#> otel 0.2.0 2025-08-29 [1] RSPM
#> patchwork 1.3.2 2025-08-25 [1] RSPM (R 4.5.0)
#> pillar 1.11.1 2025-09-17 [1] RSPM
#> pkgconfig 2.0.3 2019-09-22 [1] RSPM
#> prettyunits 1.2.0 2023-09-24 [1] RSPM
#> proxyC 0.5.2 2025-04-25 [1] RSPM (R 4.5.0)
#> purrr 1.2.1 2026-01-09 [1] RSPM
#> quanteda 4.3.1 2025-07-10 [1] RSPM (R 4.5.0)
#> quanteda.textmodels 0.9.10 2025-02-10 [1] RSPM (R 4.5.0)
#> quanteda.textstats 0.97.2 2024-09-03 [1] RSPM (R 4.5.0)
#> R.cache 0.17.0 2025-05-02 [1] RSPM
#> R.methodsS3 1.8.2 2022-06-13 [1] RSPM
#> R.oo 1.27.1 2025-05-02 [1] RSPM
#> R.utils 2.13.0 2025-02-24 [1] RSPM
#> R6 2.6.1 2025-02-15 [1] RSPM
#> RColorBrewer 1.1-3 2022-04-03 [1] RSPM (R 4.5.0)
#> Rcpp 1.1.1 2026-01-10 [1] RSPM
#> RcppParallel 5.1.11-2 2026-03-05 [1] RSPM (R 4.5.0)
#> reactable 0.4.5 2025-12-01 [1] RSPM (R 4.5.0)
#> reactablefmtr 2.1.0 2026-03-24 [1] Github (kcuilla/reactablefmtr@b271131)
#> reactR 0.6.1 2024-09-14 [1] RSPM (R 4.5.0)
#> readxl 1.4.5 2025-03-07 [1] RSPM (R 4.5.0)
#> rlang 1.1.7 2026-01-09 [1] RSPM
#> rmarkdown 2.30 2025-09-28 [1] RSPM
#> RSpectra 0.16-2 2024-07-18 [1] RSPM (R 4.5.0)
#> rstatix 0.7.3 2025-10-18 [1] RSPM (R 4.5.0)
#> S7 0.2.1 2025-11-14 [1] RSPM (R 4.5.0)
#> sass 0.4.10 2025-04-11 [1] RSPM
#> scales 1.4.0 2025-04-24 [1] RSPM (R 4.5.0)
#> seededlda 1.4.3 2025-09-28 [1] RSPM (R 4.5.0)
#> sessioninfo 1.2.3 2025-02-05 [1] RSPM
#> shape 1.4.6.1 2024-02-23 [1] RSPM (R 4.5.0)
#> skmeans 0.2-19 2026-02-04 [1] RSPM (R 4.5.0)
#> slam 0.1-55 2024-11-13 [1] RSPM (R 4.5.0)
#> SnowballC 0.7.1 2023-04-25 [1] RSPM (R 4.5.0)
#> stopwords 2.3 2021-10-28 [1] RSPM (R 4.5.0)
#> stringi 1.8.7 2025-03-27 [1] RSPM
#> stringr 1.6.0 2025-11-04 [1] RSPM
#> styler 1.11.0 2025-10-13 [1] RSPM
#> survival 3.8-6 2026-01-16 [2] CRAN (R 4.5.3)
#> tibble 3.3.1 2026-01-11 [1] RSPM
#> tidyr 1.3.2 2025-12-19 [1] RSPM (R 4.5.0)
#> tidyselect 1.2.1 2024-03-11 [1] RSPM (R 4.5.0)
#> tidytext 0.4.3 2025-07-25 [1] RSPM (R 4.5.0)
#> tokenizers 0.3.0 2022-12-22 [1] RSPM (R 4.5.0)
#> utf8 1.2.6 2025-06-08 [1] RSPM
#> V8 8.0.1 2025-10-10 [1] RSPM (R 4.5.0)
#> vctrs 0.7.2 2026-03-21 [1] RSPM (R 4.5.0)
#> withr 3.0.2 2024-10-28 [1] RSPM
#> xfun 0.57 2026-03-20 [1] RSPM (R 4.5.0)
#> yaml 2.3.12 2025-12-10 [1] RSPM
#> yardstick 1.3.2 2025-01-22 [1] RSPM (R 4.5.0)
#>
#> [1] /usr/local/lib/R/site-library
#> [2] /usr/local/lib/R/library
#> * ── Packages attached to the search path.
#>
#> ──────────────────────────────────────────────────────────────────────────────